Abstract.
대표적 DRL algorithm인 DQN, DDQN(Double DQN), D3QN(Dueling DQN)을 등장 배경, 특징, 성능의 관점에서 비교해본다.
DQN
DQN background
1. Past RL challenges to high-dimensional input
: hand-crafted feature representation에 의존하던 이전 RL은 high-dimensional input로부터 agent를 control하는 것에 취약했다.
2. DL advances & challenges to apply DL methods to RL
: DL의 발전으로 raw sensory data에서 high-level feature를 추출 가능하게 되었지만 다음의 이유로 RL에 적용이 불가능했다.
1) DL에는 많은 handlabelled training data가 필요하다.
: 그러나 RL은 frequently sparse, noisy, delayed된 환경에서 scalar reward signal을 학습할 수 있어야 한다.
2) DL에서의 data sample은 dependent하다.
: 그러나 RL은 일반적으로 data sample 간 high correlated state sequences가 발생한다.
→ high-dimensional input에 대한 control이 어려웠던 Past RL에는 발전된 DL method 적용이 불가능했다.
DQN characteristic
1. raw video data(high-dimensional input)를 CNN을 사용하여 학습
- image를 CNN을 통과시켜 feature을 추출한다.
2. weight를 update하기 위해 SGD를 사용하여 variant of Q-learning algorithm로 훈련
- optimal action-value function은 아래의 bellman equation을 따르고, RL의 기본 아이디어는 Bellman equation을 iterative하게 update하여 action-value function을 estimate하는 것이다.

- action-value를 추정하기 위해 Neural Network를 Q-network로 사용하여 일정주기마다 loss function을 minimize하며 학습한다.
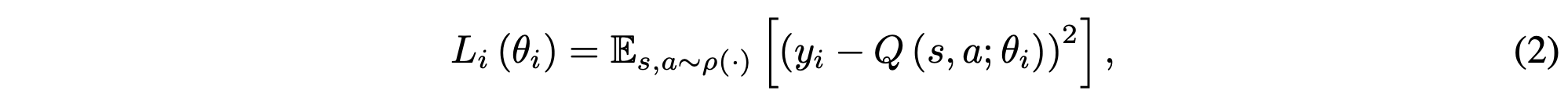
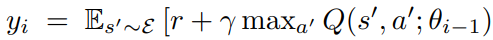
- SGD를 사용하여 최적의 weight parameter를 학습한다. 다음의 수식으로 표현된다.

→ non-linear function approximator인 Neural Network를 Q-network로 사용하고, SGD로 weight를 update한다.
3. 이전의 transitions를 randomly sampling하는 experience replay buffer 사용
- 최근 N개의 experience(e_t = (s_t, a_t, r_t, s_(t+1))를 각 time-step마다 memory에 저장한다. 학습 시, sample를 random하게 추출하여 mini-batch-update에 사용한다. 이러한 방식은 online Q-learning보다 다양한 이점을 지닌다.
1) 각 experience는 많은 weight update에 사용 가능하다.
: 데이터를 효율적으로 사용 가능하다.
2) 표본을 random하게 추출함으로써, weight update 분산을 줄인다.
: 연속된 sample에서의 학습은 sample 간 high correlation 때문에 비효율적이다.
3) 학습을 안정적으로 만든다.
: on-policy 학습의 경우, 현재 parameter가 다음 data sample을 결정하며 이는 local minimum에 빠질 가능성이 높다. 그러나 experience replay를 사용하면 behavior distribution이 평등해진다.
→ experience replay buffer를 사용하면 off-policy 학습에 효과적이다.
4. 하나의 network가 아닌 target network를 사용
- update를 하는 동안 target을 계산하는 y_i 식에서 계산에 사용되는 parameter를 고정한다는 의미이다. 즉, policy network parameter θ_i가 update하는 동안, 매번 target network parameter θ_(i-1)를 고정한 뒤 maximum Q를 선택한다.
- 만약 이렇게 하지 않는다면, target Q-value를 구할 때, parameter에 영향을 크게 받아 무한한 feedback loop에 빠지게 되고, estimated Q-value가 target으로 안정적으로 update되지 않을 수 있다.
→ target의 값을 구할 때, update할 target network의 parameter는 fix하고 update한다.
DQN algorithm

1. epsilon greedy 방식의 action 선택

- 한 episode 내에서 time-step 마다 반복
- e 확률로 action a_t 선택하거나 DQN으로 추정한 max Q-value action a_t를 선택
- 선택된 a_t를 emulator에서 simulate 한 뒤, reward r_t와 s_(t+1)을 관찰
2. Replay buffer에 transition 저장과 random sampling

- transition (s_t, a_t, r_t, s_(t+1))를 memory D에 저장
- memory D로부터 uniformly random하게 minibatch만큼 샘플링
3. target network's value y_i와 policy network's estimated value 차이 비교

- target value인 y_i는 fixed parameter target netwowrk에서 판단 되고, 차이를 이용해 SGD로 최적화
DQN results
- 학습 중, predicted Q에 대해 순조롭게 개선되며, 모든 실험에서 발산하지 않았다.

- 각종 algorithm 비교를 통한 결과 평가를 보면, DQN의 성능이 압도적이었다.

→ 이론적 수렴 보장이 없음에도 불구하고 DQN을 사용하여 안정적인 방식으로 대규모 NN을 훈련할 수 있다.
DQN conclusion
- model-free, off-policy algorithm
| DQN | |
| Background | high-dimensional input에 대한 control이 어려웠던 Past RL에는 발전된 DL method 적용이 불가능 |
| Characteristic |
1. raw video data(high-dimensional input)를 CNN을 사용하여 학습 |
| 2. weight를 update하기 위해 SGD를 사용하여 variant of Q-learning algorithm로 훈련 | |
| 3. 이전의 transitions를 randomly sampling하는 experience replay buffer 사용 | |
| 4. 한개의 policy network가 아닌 fixed target network에서 maximum Q를 선택 | |
| Algorithm |
- epsilon greedy 방식의 action 선택 |
| - Replay buffer에 transition 저장과 random sampling | |
| - target network's value y_i와 policy network's estimated value 차이 비교 | |
| Results | DQN 이전 각종 algorithm과 비교 결과, DQN의 성능이 압도적 |
DDQN(Double DQN)
DDQN background
1. DQN problem
: Q-learning algorithm은 underestimated values보다 overestimated values를 더 선호하는 경향이 있는 estimated action value에 대한 maximize 단계를 포함하기 때문에 때때로 비현실적으로 높은 action value를 학습하는 것으로 알려졌다.
2. Question about overestimation
: 지나치게 낙관적인 value overestimate가 반드시 그 자체로 문제가 되는 것은 아니지만, overestimation가 균일하지 않은 경우 policy quality에 부정적인 영향을 끼칠 수 있다.
→ Q-learning에서 overestimation 문제가 발생하였고, 이는 때때로 DQN의 성능에 부정적인 영향을 미친다.
DDQN characteristic
1. target network max 연산을 action evaluation과 action selection으로 으로 분해
- 기존 DQN target y_i는 target network의 parameter를 사용하여 Q-value를 evaluate & estimate하였다. 이는 동일한 parameter θ_i를 사용하면 action을 estimate할 때도, greedy policy가 적용되기 때문에 overestimate가 발생한다.
- DDQN에서는 policy network에서 Q-value를 evaluate하고, target network에서 Q-value를 estimate한다. target network는 env와 상호작용을 하지 않기 때문에, action을 estimate할 때 greedy policy가 미적용된다. 따라 Q-value를 fair하게 추정할 수 있다.
- target network는 env와 상호작용하지 않는다.

→ policy network에서의 evaluation과 target network에서의 estimation을 통해 overestimation을 방지한다.
2. target network에 대한 update는 policy network의 주기적 복사본으로 유지
- 기존 DQN prarmeter θ_i가 update하는 동안, 매번 target network θ_(i-1)를 고정한 뒤 maximum Q를 선택하였다.
- DDQN에서는 N updates 이후, policy network를 target network로 복사한다.
DDQN algorithm

1. action evaluation & estimation 후 loss 값 계산
- policy network parameter로 action evaluation 후 해당 action을 target network로 전달
- target network는 Q-value를 estimate
- policy network estimated Q-value와 target network estimated Q-value의 loss 계산
2. target network는 N updates마다 copy
DDQN results
- DDQN 사용 시 DQN보다 학습이 훨씬 더 안정적이고 성능이 뛰어남을 보인다.
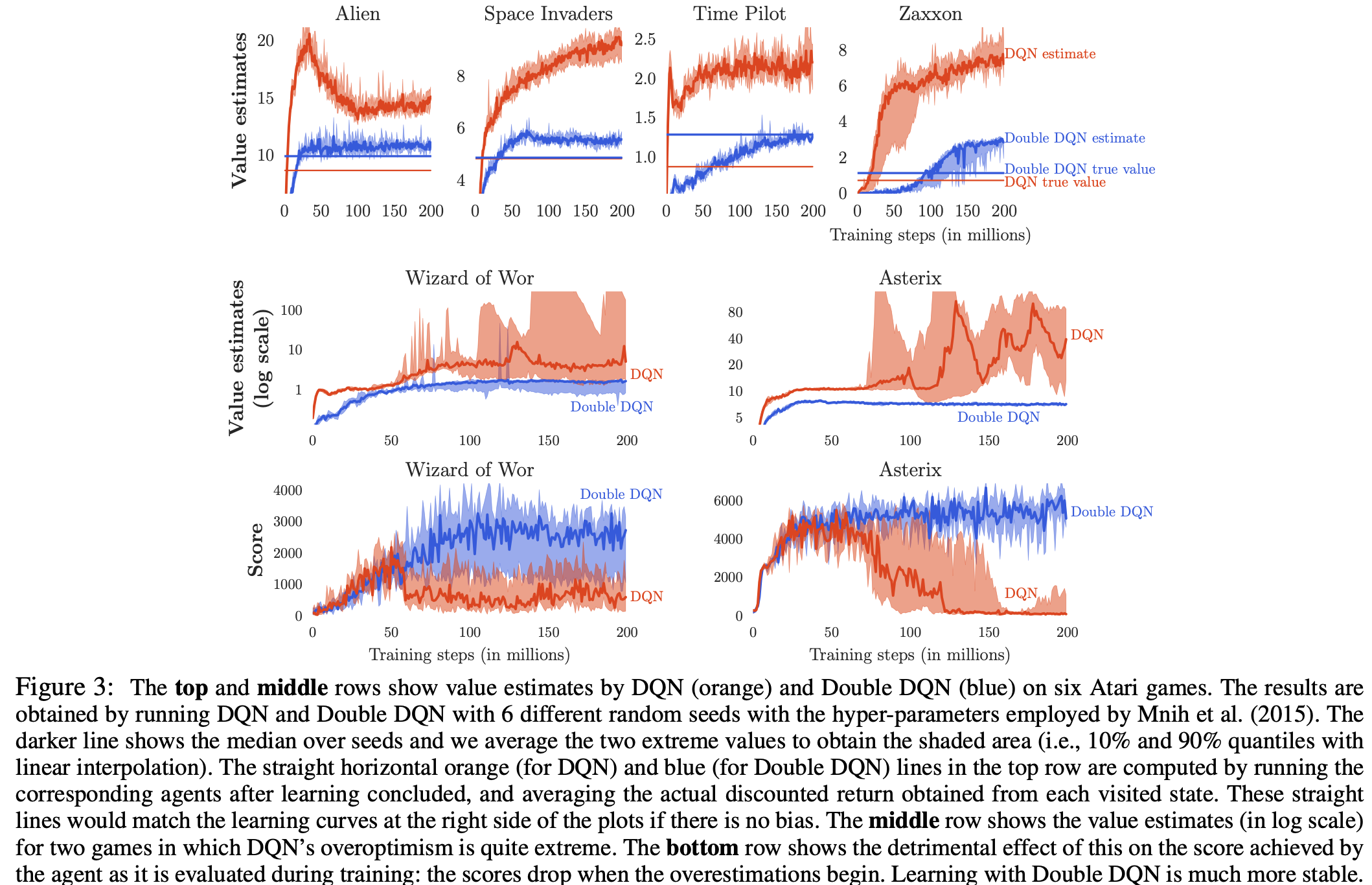

→ DDQN이 DQN보다 더 나은 estimate를 생성할 뿐만 아니라 더 나은 policy를 생성한다.
DDQN conclusion
- model-free, off-policy algorithm
| DDQN | |
| Background | Q-learning에서 overestimation 문제가 발생하였고, 이는 때때로 DQN의 성능에 부정적인 영향을 미친다. |
| Characteristic |
1. target network max 연산을 action evaluation과 action selection으로 분해 |
| 2. target network에 대한 update는 policy network의 주기적 복사본으로 유지 | |
| Algorithm |
- action evaluation & estimation 후 loss 값 계산 |
| - target network는 N updates마다 copy | |
| Results | DDQN이 DQN보다 더 나은 estimate를 생성할 뿐만 아니라 더 나은 policy를 생성한다. |
D3QN(Dueling DQN)
D3QN background
1. Value function vs. Advantage function
ex. Atari Enduro game
기존의 value network에서는 바로 앞에 차가 있던 말던 새 자동차가 등장하는 지평선 및 점수에 주의를 기울이지만, advantage network에서는 앞 차가 없을 경우 action 선택이 실질적으로 관련이 없기 때문에 visual input에 주의를 기울이지 않는다. 그러나 바로 앞에 차가 생기면 주의를 기울이고 action 선택을 적절하게 만든다.
: 기존의 value network과는 다르게 advantage network는 각 state에 대한 action의 효과를 직관적으로 학습하지 않고도 어떤 state가 가치있는지 학습이 가능하다. 해당 action이 relevent way로 환경에 영향을 미치지 않는 states에서 특히 유용하여 새로운 dueling architecture를 제안한다.
→ 실험에서, 중복되거나 유사한 action이 학습 문제에 추가되어도, Dueling architecture는 policy evaluation 중에 올바른 action을 더 빨리 식별할 수 있다. 더 이상 많은 states에서 각 action 선택의 가치를 평가하는 것이 불필요하다.
D3QN characteristic
1. state-value & state-depentent action advantages를 분리하여 새로운 value 사용
- Dueling network는 value & advantage function을 나타내는 두개의 stream로 구성되어 공통의 convolutional feature learning module을 거쳐 state-value function과 advantage function에 대한 별도의 estimate를 자동으로 생성한다.

- state-value function V는 특정 state s에 있는 것이 얼마나 좋은지를 측정하고, action-value function은 이 state에 있을 때 특정 action을 선택하는 value를 측정한다. 다음과 같이 정의된다.
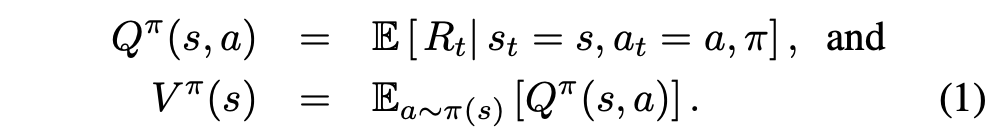
- advantage function은 action-value function에서 state-value function을 빼서 각 action의 중요성에 대한 상대적인 measure을 측정한다. 다음과 같이 정의된다.

- 추가로 아래의 식을 만족한다. deterministic policy a* = argmax_a'∈A Q(s,a')에서 Q(s,a*) = V(s)를 따르기 때문이다.

→ 어떤 states에서 어떤 action을 취해야 하는지 아는 것이 가장 중요하지만 다른 많은 states에서는 action 선택이 무슨 일이 일어나는지에 영향을 미치지 않는다.
2. prioritized replay buffer 사용
- 균일한 experience replay 보다 더 빠른 학습과 더 나은 final policy quality 결과를 보이는 PER을 사용한다. 학습 진도가 높을 것으로 예상되는 experience tuples의 재생 확률을 높이는 것으로 proxy of absolute TD-error로 측정한다.
D3QN algorithm
1. 새로운 V + A = Q value 사용과 unidentifiable 문제 해결
- advantage function 정의를 통해 다음과 같은 aggregating module 설계가 가능하다. 이 때, Q는 true Q-function의 parameterized estimate이다. 이 때, V와 A 모두 합리적인 estimate를 제공한다고 결론지을 수 없다.

- 계산된 Q value는 어느 V와 A에서 유도되었는지 알 수 없는 unidentifiable 문제가 발생하고, 해결을 위해 기준점을 정해야 한다. advantage function이 선택한 action에서 advantage가 0이 되도록 강제하여 아래와 같이 식을 변경하면 optimal action a*를 선택하였을 때, Q = V가 되도록 만들 수 있다.

- 또한 각각의 stream이 value와 advantage를 적절하게 나타냄을 알 수 있다. 이렇게 되면 계산된 Q를 보고 가장 높은 값을 가질 때가 optimal action이며, 그 값이 V임을 파악할 수 있고, identifiability issue를 해결할 수 있다.
- 위 max 연산처럼 정확히 기준점을 추측할 순 없지만, average 연산은 최적화 과정에서 이득을 보아 논문 내 실험에서는 아래의 방식을 채택하였다.

D3QN results
- 다른 algorithm과의 결합이 쉬운 D3QN의 장점을 이용한 PER과 gradient clipping을 합친 모델의 성능이 가장 뛰어났다.
- baseline DDQN을 Single이라고 하였을 때, gradient clipping을 적용한 모델을 Single Clip, PER을 적용한 모델을 Prior. Single로 명명한 뒤 실험 결과이다.

- Dueling architecture는 일부 algorithm 개선과 결합되어 Atari domain에서 Deep RL에 대한 기존 접근 method에 비해 극적인 개선을 이루어냈다.
D3QN conclusion
- model-free, off-policy algorithm
| D3QN | |
| Background | 많은 states에서 각 action 선택의 가치를 평가하는 것이 불필요하다. |
| Characteristic |
1. state-value & state-depentent action advantages를 분리하여 새로운 value 사용 |
| 2. prioritized replay buffer 사용 | |
| Algorithm | - 새로운 V + A = Q value 사용과 unidentifiable 문제 해결 |
| Results | Dueling architecture는 일부 algorithm 개선과 결합되어 DDQN보다 극적인 개선을 이루어냈다. |
Note
- model-free, off-policy algorithm
| DQN | |
| Background | high-dimensional input에 대한 control이 어려웠던 Past RL에는 발전된 DL method 적용이 불가능 |
| Characteristic |
1. raw video data(high-dimensional input)를 CNN을 사용하여 학습 |
| 2. weight를 update하기 위해 SGD를 사용하여 variant of Q-learning algorithm로 훈련 | |
| 3. 이전의 transitions를 randomly sampling하는 experience replay buffer사용 | |
| 4. 한개의 policy network가 아닌 fixed target network에서 maximum Q를 선택 | |
| Algorithm |
- epsilon greedy 방식의 action 선택 |
| - Replay buffer에 transition 저장과 random sampling | |
| - target network's value y_i와 policy network's estimated value 차이 비교 | |
| Results | DQN 이전 각종 algorithm과 비교 결과, DQN의 성능이 압도적 |
| DDQN | |
| Background | Q-learning에서 overestimation 문제가 발생하였고, 이는 때때로 DQN의 성능에 부정적인 영향을 미친다. |
| Characteristic |
1. target network max 연산을 action evaluation과 action selection으로 분해 |
| 2. target network에 대한 update는 policy network의 주기적 복사본으로 유지 | |
| Algorithm |
- action evaluation & estimation 후 loss 값 계산 |
| - target network는N updates마다 copy | |
| Results | DDQN이 DQN보다 더 나은 estimate를 생성할 뿐만 아니라 더 나은 policy를 생성한다. |
| D3QN | |
| Background | 많은 states에서 각 action 선택의 가치를 평가하는 것이 불필요하다. |
| Characteristic |
1. state-value & state-depentent action advantages를 분리하여 새로운 value 사용 |
| 2. prioritized replay buffer 사용 | |
| Algorithm | - 새로운V + A = Q value사용과unidentifiable 문제 해결 |
| Results | Dueling architecture는 일부 algorithm 개선과 결합되어 DDQN보다 극적인 개선을 이루어냈다. |
'논문 리뷰 > 개인 정리' 카테고리의 다른 글
| Markov Models & Hidden Markov Models (1) | 2022.09.20 |
|---|
댓글