Main Paper https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9043893
Deep Reinforcement Learning for MultiagentSystems: A Review of Challenges,Solutions, and Applications
Abstract
RL algorithm은 sequential decision-making problem을 해결하는데 사용되어 왔지만, high-dimensional env를 다룰 때 어려움에 직면했다. 최근 deep-learning의 발전으로 RL은 challenging env에서 효과적으로 수행가능한 정교하고 유능한 agent의 optimal policy를 제공하게 해준다. 이 논문은 complex tasks를 해결하기 위해 multiple agents들이 communicate & cooperate 해야하는 상황에 관련된 deep RL에 대해 살펴본다. non-stationary, partial observability, continuous state & action spaces, multi-agent training schemes, multi-agent transfer learning을 포함하여 MADRL과 관련된 문제에 대한 다양한 approach가 제공된다. 검토된 method의 장단점을 분석하고 해당 application을 탐색하면서 논의한다. 이 검토는 다양한 MADRL method 방식에 대한 통찰력을 제공하고 더욱 유용한 multi-agent learning method 개발로 이어질 수 있다.
Introduction
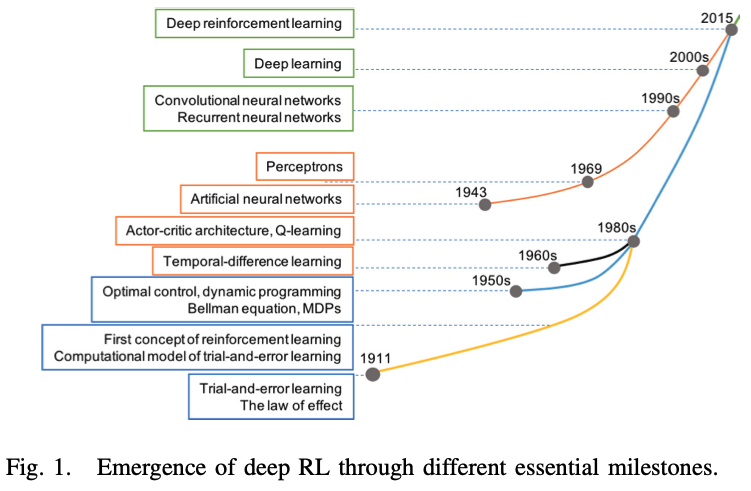
Milestones of development of RL
RL의 발전과 approach의 변화
1) trial-and-error(TE) procedure로부터 시작
2) psychology에서 유래된 temproal-difference(TD) learning mechanism을 computational model of TE learning에 통합
=> TE learning을 large system에 feasible
3) Q-learning을 형성하기 위해, TD learning과 함께 Bellman equation, Markov decision process(MDP)를 포함한 optimal control 이론이 등장
=> 이후 Q-learning은 다양한 task를 풀기 위해 적용되어 왔지만, 계산의 양이 급격하게 증가하는 high-dimensional problem는 풀지 못하는 curse of dimensionality 발생
4) curse of dimensionality를 극복하기 위해 deep learning과 RL을 결합
Usecase of RL
RL은 심리학의 동물 학습에서 유래하므로 env과의 interaction에서 long-term profit을 극대화하는 action을 선택하는 인간 학습 능력을 모방할 수 있다. 따라서 robotics나 autonomous systems에서 널리 사용되고 있다.
modern RL은 성능이 뛰어난 deep RL인 DQN으로 해결한 atari game series부터, AlphaGo, physics problems, 3D-maze problem등을 해결하였다. 더 중요하게, deep RL은 optimal control of non-linear system, pedestrian regulation, traffic grid signal control과 같은 실용적인 real-world preoblem을 해결하기 위한 유망한 approach가 되었다.
from Single agent RL to Multi-agent RL
real-world problem이 점점 더 복잡해짐에 따라 single deep RL agent가 대처할 수 없는 상황이 발생한다. 이러한 상황에서 multi-agent system(MAS)의 적용이 필요하다. MAS에서 agent는 최상의 결과를 얻기 위해서 cooperate or compete 해야한다. 이러한 MAS에서 deep RL을 사용하는 multi-agent deep RL(MADRL) 연구가 진행중이다.
single agent domain에서 multi-agent domain으로 변경하게 되면 여러 관점에서의 문제가 발생한다. previous survey에서는 예를들어 다음과 같은 사항들을 고려했었다.
1) stability and adapation aspects of agents
2) evolutionary dynamics
3) emergent behavior of communication and cooperation learning perspectives
4) knowledge reuse autonomy in MARL
이 논문에서는 MADRL의 technical challenge와 각 challenge에 대한 deep RL approach를 살펴본다. non-stationary, partial observability, continuous state & action spaces, multi-agent training schemes, multi-agent transfer learning을 포함한 MADRL approach뿐만 아니라 다양한 분야에서의 MADRL application도 분석한다.
DEEP RL: MULTIAGENT
MAS는 individual agent의 cooperation을 통해 complex task를 해결한다는 점에서 큰 주목을 받았다. MAS 내에서 agent들은 서로 communicate하고 env와 interact한다. multi-agent learning domain에서 MDP는 stochastic game or Markov game으로 generalized 된다.

: number of agent

: discrete set of environmetal states

: set of actions for each agent

: joint action set for all agent

: state transition probability function

: reward function0

: value function of each agent, dependent on joint action & joint policy
MADRL: Challenge & Solutions
1. Non-stationary
multiple agent를 제어하는 것은 single agent 설정과 비교하여 다음과 같은 문제가 발생한다.
(1) heterogenity(이질성) of agents
(2) defining sutible collective goals
(3) compact representation 설계가 요구되는 large number of agents에 대한 scalability
multi-agent domain에서 agent는 self action뿐만 아니라 other agent's action도 관찰한다. agent 간의 learning은 모든 agent가 잠재적으로 서로 interaction하고 동시에 learning 하기 때문에 복잡하다.여러 agent 간의 interaction은 지속적으로 env를 재구성하고, non-stationary하게 만든다. 이 경우 agent간의 learning은 때때로 agent policy를 변경하고, other agent의 optimal policy에 영향을 줄 수 있다. task의 estimated potential reward of an action은 정확하지 않으므로, multi-agent 설정의 특정 시점에서 좋은 policy는 미래에 유지되지 않는다. single-agent 설정에 적용된 Q-learning convergence 이론은 non-stationary env에서 Markov property가 더 이상 유지되지 않기 때문에 MADRL 문제에 대해 보장되지 않는다. 따라서 collecting & processing information은 agent's stability에 영향을 미치지 않도록 일정 주기로 수행되어야 한다.
- for Non-stationary
independent Q-learning or experience replay-based DQN은 non-stationary env를 위해 설계되지 않았다. 따라서 몇가지 변형을 제안하여 MAS's non-stationary problem을 해결한다.
(1) DRUQN(deep repeated update Q-network)
: RUQL(repeat update Q-learning) model를 기반으로 개발되었다. action select probability에 반비례하는 action value를 update하여 policy bias를 회피한다.
(2) DLCQN(deep loosely coupled Q-network)
: loosely coupled Q-leraning에 의존하며, 이는 negative reward와 observation을 사용하여 각 agent에 대한 independence degree를 조정한다. 이 independence degree를 통해, agent는 독립적으로 행동해야하는지 아니면 다른 상황에서 다른 agent와 협력해야하는지 결정하는 법을 배운다.
(3) multiagent concurrent DQN
: MADRL에서 DQN의 replay buffer를 안정화하기 위해 두가지 방법을 도입했다.
1) importance sampling approach를 사용하여 오래된 데이터를 자연스럽게 소멸시킨다.
2) fingerprint를 사용하여 replay buffer에서 검색된 sample의 나이를 명확하게 지정한다.
multi-agent의 concurrent learning으로 인한 non-stationary를 처리하기 위해 최근에는
(4) LDQN(lenient-DQN)
: experience replay memory로부터 sampled 된 policy update를 조정하기 위해, decaying temporature values로 leniency를 적용한다. leniency는 learning agent가 co-learner의 poor action을 무시하여, 낮은 rewards로 이어지는 situation을 describe하고, co-learner가 미래에 자신의 action을 improve 할 수 있기를 희망하면서 여전히 협력한다.
=> other agent가 poor action을 수행하더라도, 그 agent를 무시하는 것이 아닌 미래에 개선될 것이라고 가정하고 interaction한다.
추가적으로 해당 paper experiment의 stochastic reward env에서 LDQN은 HDQN(hysteretic-DQN)과 비교했을 때, 좀 더 우수한 성능을 보였다. scheduled replay starategy와 함께 leniency 개념은 MAS non-stationary를 처리하기 위해 WDDQN(weighted DDQN)에도 통합되었다.
2. Partial Observability
agent가 env를 부분적으로 관찰 할 수 있는 상황이 다수 존재한다. 즉, agent는 env와 interaction 할 때, complete information of state를 알 수 없다. 이러한 상황에서 agent는 env의 partial information을 관찰하고 각 time-step에서 best decision을 내려야 한다. 이는 POMDP를 사용하여 모델링이 가능하다.
- for Partial Observability
POMDP 처리를 위해 다양한 deep RL model이 제안되었다.
(1) DRQN
: long short-term memory network를 기반으로 하여, recurrent structure를 통해 POMDP env에서 좋은 성능을 보였다. 이는 multi-agent POMDP problem을 처리하기 위해 DDRQN(deep distributed recurrent Q-network)으로 확장된다. DDRQN의 성공은 다음의 특징에 달려있다.
1) last-action inputs
: 각 agent의 last-action을 next-step에 대한 입력으로 제공한다.
2) inter-agent weight sharing
: 모든 agent가 훈련 과정에서 학습된 하나의 network weight만 사용함을 의미한다. agent가 same set of actions를 가지고 있다는 가정하에, 가중치 공유는 학습할 매개변수의 수를 줄이기 때문에 학습 시간을 단축한다.
3) disabling experience replay
: DQN의 repaly buffer를 제외한다.

: DDRQN's Q function, where each agent receives its own index m as the input
(2) extended curriculum learning method
: policy gradient, TD error, AC method의 deep RL classes을 통합한다. curriculum principle은 complex task 수행 전, simple task를 먼저 수행하는 것이다.
=> 많은 agent를 수용하도록 확장하기 전에, 적은 수의 agent가 처음에 협업하는 MAS env에 적합하다.
(3) DRPIQN(Deep recurrent policy inference Q-network)
: training process에서 network's attention을 policy features와 own Q-values에 적용하여 학습된다.
(4) multitask MARL(MT-MARL)
: multitask, multi-agent problem으로 확장되어 hysteretic learners, DRQNs, distillation, experience replay strategy의 decentralized extension인 concurrent experience replay trajectories(CERTs)를 통합한다. agent는 partial observability 때문에 task identity가 명시적으로 제공되지 않아도, complete set of decentralized POMDP tasks를 sparse rewrd로 cooperative하게 학습한다. 그러나 이 method는 heterogeneous agent가 있는 env에서는 불가능하다.
- for Noisy Observations
agent가 env의 true state와 약한 상관관계가 있는, 매우 noisy한 관찰을 처리해야하는 경우가 있다.
(1) MADDPG(Deep Deterministic Policy Gradient)
: DDPG와 agent의 circumstances를 전달할 communication 매체를 결합한다. agent는 자신의 관찰이 다른 agent와 공유하기 위해 유익한지 여부를 결정해야 하며, communication policy는 experience를 통해 main policy와 동시에 학습된다.
(2) BAD(Bayesian action decoder)
: public belief는 env에서 공개적으로 관찰할 수 있는 feature으로, public belief MDP는 이를 얻기 위해 approximate Bayesian update를 사용한다. BAD는 최적의 policy를 효과적으로 학습하기 위해, factorized & approximate belief state에 의존한다.
3. MAS Training Schemes
single-agent에서 multi-agent로의 기본적인 확장은 다른 agent를 env의 일부로 고려하는 것이다. 그러나 이는 overfitting에 취약하고 계산 비용이 많이 들기 때문에 관련된 agent의 개수가 제한된다. 대안으로는 open communication channel을 통해 centralized learning & decentralized execution(CTDE)를 적용하여 agent group을 동시에 훈련한다.
각 agent의 local observation을 기반으로 action을 취할 수 있는 decentralized policy는 partial observability와 limited communication channel에서 이점이 존재한다. centralized learning의 decentralized policy는 channel constraints가 없고, extra state information을 사용할 수 있는 상태에서도 학습이 가능하기 때문에 multi-agent의 표준 패러다임이 되었다.
MAS에서 다음과 같이 각기 다른 training schemes들이 연구되었다.
1) Centralized Policy
: 모든 agent의 joint observation에서 joint action을 얻으려고 한다.
2) Concurrent Learning
: joint reward signal를 사용하여 agent를 동시에 훈련시킨다. 각 agent는 local observation을 기반으로 자체 policy를 독립적으로 학습한다.
3) Parameter Sharing
: 각 agent는 고유한 observation을 얻을 수 있지만, 모든 agent의 experience들을 사용하여, agent들을 동시에 훈련할 수 있다.
decentralized policy execution을 통해, parameter sharing을 사용하여 single-agent deep RL algorithm을 확장하여 multi-agent system까지 수용 가능하다. 특히 PS-TRPO(parameter sharing+TRPO)이 제안되었으며, 이는 partial observability에서 high-dimensional observations & continuous action spaces를 다룰 때 뛰어난 성능을 보인다.
- for improving agent learning communication with centralized learning approach
(1) RIAL(reinforced interagent learning)
: deep Q-learning은 partial observability issue를 해결하기 위한 recurrent structure을 가지고 있고, 여기서 independent Q-learning은 개별 agent가 자신의 network parameter를 학습한다.
(2) DIAL(differentiable interagent learning)
: channel을 통해 agent 간의 gradient를 push하여 end-to-end backpropagation을 허용한다.
(3) CommNet(Communication neural net)
: dynamic agent가 fully-cooperative task에 대한 policy와 함께 continuous communication을 학습한다.
(4) DRON(Deep Reinforcement Reverse Network)
: domain knowledge 없이, opponent's policy와 action을 공동으로 학습하기 위해, 상대 agent의 observation을 DQN으로 인코딩한다.
(5) MS-MARL
MAS의 communication problem을 해결하기 위해, decentralized & centralized perspectives 모두 hierarchical master-slave architecture에 통합한다. master agent는 salve agent로부터 메시지를 수신하고 집합적으로 처리한 다음, 각 slave agent에 고유한 지시 메시지를 생성한다. slave agent는 자신의 정보와 master agent의 instructive 메시지를 사용하여 action을 취한다. 이 모델은 large multi-agent가 있는 경우, peer-to-peer architecture에 비해 MAS에서 크게 communication 부담을 줄인다.
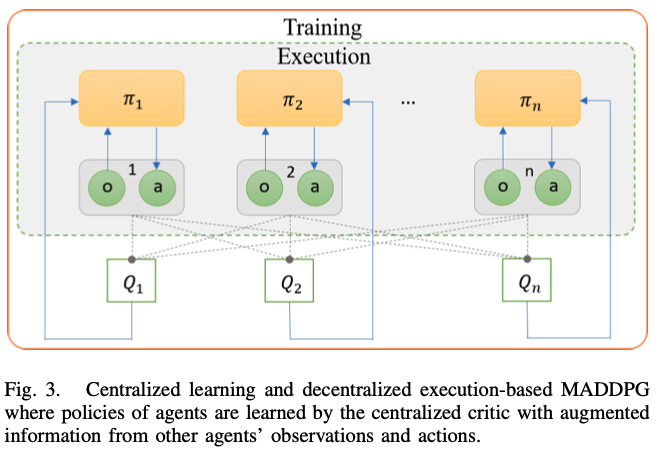
(6) MADDPG(Multiagent Deep Deterministic Policy Gradient)
: AC policy gradient algorithm에 기반한 방법이다. actor가 자신의 local observation을 기반으로 action을 취하는 동안, critic이 extra information을 사용하여 교육 프로세스를 용이하게 하는 central learning & decentralized execution 패러다임을 특징으로 한다. Fig. 3.은 execution 단계에서 actor만 사용되는 MADDPG의 decentralized actor & centralized critic 구성요소를 보여준다.
(7) COMA(Counterfactual Multiagent)
: 다른 multi-agent AC method이며 centralized learning & decentralized execution이다. MADDPG와 달리, COMA는 agent가 cooperative env에서 joint action으로 생성된 global reward에서 team success에 대한 기여도를 계산하기 어려운 multi-agent credit assignment problem을 처리할 수 있다. 그러나 COMA는 discrete action space에만 집중하는 반면, MADDPG는 continuous policy를 효과적으로 학습할 수 있다.
4. Continuous Action Spaces
대부분의 deep RL model은 discrete spaces에 만 적용이 가능하다. 예를 들어, DQN은 high-dimensional observation spaces를 처리할 수 있지만, 이는 discrete and low-dimensional action spaces problem에만 제한된다. DQN은 action value가 최대인 action을 찾는것을 목표로 하므로, continuous action(state) spaces의 모든 step에서 iterative optimization이 필요하다. action space를 discretizing 하는 것은 deep RL method를 continuous domain에 적용 가능한 solution이다. 그러나 이는 curse of dimensionality와 같은 문제들을 발생시킨다. 즉 자유도의 수에 대해 action number이 기하급수적으로 증가한다.
(1) TRPO(Trust Region Policy Optimization)
: stochastic control policy을 최적화하기 위해 continuous states and action으로 확장된다.
(2) DDPG(Deep Deterministic Policy Gradient)
: off-policy algorithm으로 AC architecture를 가지며 continuous action space를 처리한다. DPG(Deterministic Policy Gradient)에 기반하여, critic에서 DQN learning을 유지하면서 parameterized actor function을 사용하여 state를 specific action에 deterministically하게 매핑한다. 그러나 이 approach는 model-free RL method에서 흔히 볼 수 있는 것처럼, 많은 training episodes를 필요로 한다.
(3) RDPG
: DDPG를 반복적인 DPG로 확장하여 partial observation이 가능한 continuous action spaces problem을 처리한다.
(4) PS-TRPO
: TRPO을 기반으로 하여, continuous action spaces를 효과적으로 다룬다.
5. Transfer Learning for MADRL
Q-network 또는 일반적인 single agent deep RL model을 훈련하는 것은 종종 계산 비용이 많이 든다. 특히 MAS env에서는 더욱 심해진다. 여러 deep RL model의 훈련 과정에서 성능을 개선하고 계산 비용을 줄이기 위해 여러 연구에서 deep RL에 대한 transfer learning을 촉진했다.
(1) policy distillation & progressive neural network
: 계산적으로 복잡하고 비용이 많이 드는 단점이 존재한다.
(2) another policy distillation
: 훈련 시간을 줄이고 DQN보다 성능이 우수하지만 exploration strategy가 효과적이지 않다.
(3) actor-mimic
: model이 그렇게 복잡하지는 않지만, 많은 env에서 좋은 성능을 얻었다. 그러나 이 방법은 source & target task 간에 충분한 유사성이 필요하며, negative transfer에 취약하다.
multi-agent env는 image와 같은 표현으로 reformulated 되고, CNN은 문제의 각 agent에 대한 Q-value를 추정하기 위해 사용된다. 이 approach는 transfer learning method를 사용하여, 훈련 프로세스의 속도를 높일 수 있는 경우 MAS의 scalability problem을 해결할 수 있다. different but related env에서 훈련된 policy network는 계산 비용을 줄이기 위해, 다른 agent의 학습 프로세스에 사용된다. pursuit-evasion problem에 대해 수행된 실험은 multi-agent domain에서 transfer learning approach의 효율성을 보여준다. Table 3.에는 다양한 multi-agent problem을 다루는 검토된 논문 요약이 나와있다. multi-agent env에서 policy-based or AC method가 적절하게 탐색되지 않은 반면, DQN의 많은 확장이 논문에서 제안되었음을 알 수 있다.

'논문 리뷰 > Research Paper' 카테고리의 다른 글
| Contrastive Clustering (0) | 2025.03.05 |
|---|---|
| CLAD: Robust Audio Deepfake Detection Against Manipulation Attacks with Contrastive Learning (0) | 2025.02.26 |
댓글