목차
Abstract
오디오 딥페이크의 증가로 보안 위협이 커지며, 기존 탐지 시스템이 조작 공격에 얼마나 취약한지 연구가 부족한 상황임. 기존 탐지 시스템은 유용하지만 단순한 manipulation attacks으로도 탐지를 우회할 수 있고, 본 연구에서는 해결을 위해 CLAD 탐지 모델을 제안함. CLAD는 contrastive learning을 활용하여 manipulation으로 인한 변화를 최소화하고, length loss를 추가하여 탐지 성능을 향상시킴. 기존 모델들은 manipulation attacks에서 상당히 취약했으나, CLAD는 모든 테스트에서 높은 견고성을 입증함.
1. Introduction

기술의 발전과 더불어 오디오 딥페이크 관련 범죄가 확산되었으며, 연구자들은 이를 탐지하기 위해 각종 acoustic feature을 활용하거나 딥러닝 접근 방식을 채용함. 이들은 ASVspoof과 같은 대규모 공개 데이터셋에서 뛰어난 성능을 보였으나 기존 탐지 방법들은 합성 기술의 raw output을 평가 대상으로 삼고 있고, 이는 단순하지만 현실적인 manipulation attacks에 오히려 더 취약함.
기존 탐지 방법들에는 탐지 시스템 우회를 위한 adversarial attacks을 사용하였으나, 비용이 많이 들며 표적 시스템에 대한 사전 지식을 필요로 하는 경우가 많음. 그러나 manipulation attacks은 현실적이고 비용이 적게 들어 심각한 위협이 됨. 7가지 manipulation 기법(noise injection, volume control, fading, time stretching, resampling, time shifting, echoes adding)을 설계하여 널리 사용되는 탐지 기법들의 견고성을 평가한 결과, 기존 탐지 시스템들이 이러한 manipulation attacks에 취약하다는 것을 확인함.
본 연구에서는 CLAD (Contrastive Learning-based Audio deepfake Detector)를 제안함. CLAD는 contrastive learning을 활용하여 manipulation attacks에 강한 오디오 encoder를 학습하며, length loss을 적용하여 실제 오디오와 딥페이크 오디오를 명확히 구별하도록 설계됨. CLAD는 기존 탐지 기법들보다 manipulation attacks에 대한 견고성이 높으며, 탐지 성능이 크게 향상됨을 입증함.
Contribution
- 기존 오디오 딥페이크 탐지 방법이 오디오 manipulation attacks에 대해 얼마나 견고한지를 최초로 종합적으로 연구하였으며, 간단한 manipulation만으로도 탐지 시스템에 심각한 위협이 될 수 있음을 밝혀냄.
- CLAD 모델에 다양한 오디오 manipulation에 대해 신뢰할 수 있는 feature를 생성하기 위해 contrastive learning을 도입하여 강력한 encoder를 학습함. 또한, encoder의 정확도 향상을 위해 length loss이라는 새로운 학습 전략을 설계하여 encoder의 성능을 강화함.
- 다른 딥페이크 탐지 모델들과 다양한 시나리오에서의 종합적인 평가에서 CLAD는 manipulation attacks에 대해 효과적이고 견고한 성능을 보였으며, 모든 attacks에 대해 FAR (False Acceptance Rate)을 1.63% 이하로 유지하는 우수한 성능을 기록함.
2. Manipulation Attacks
A. Manipulations
아래는 오디오 처리에서 널리 사용되는 방법들로 구현이 용이하며, 오디오 딥페이크의 본래 목적과 모순되지 않도록 결과적으로 생성된 오디오가 인간의 청각적 지각에서 자연스럽게 유지됨.
- Noise injection: SNR (Signal-to-Noise Ratio)를 조정하여 오디오 신호에 추가적인 노이즈를 적용함. WN (White Noise)와 EN (Environmental Noise)를 고려하였으며, 바람, 발소리, 숨소리, 기침, 빗소리, 시계 초침 소리, 재채기 소음 등의 환경 소음을 사용함.
- Volume Control: 음성 신호의 의미는 변경하지 않으면서, 단순히 음성 신호의 크기만 조절함.
- Fading: 오디오의 시작과 끝에 fade-in과 fade-out을 추가함. 5가지 다른 페이딩 형태로 linear, logarithmic, exponential, 1/4 quarter sinusoidal, 1/2 half sinusoidal를 적용함 .
- Time Stretching: 오디오 신호의 속도나 지속 시간을 변경하면서도 pitch는 유지함.
- Resampling: 오디오 신호의 sampling rate를 변경함.
- Time Shifting: time domain에서 오디오를 이동시키는 기법으로, 신호를 특정 시간만큼 앞당기거나 지연시킴.
- Echoes Adding: 원본 신호의 지연된 버전과 감쇠된 버전을 생성하여 합치는 방식으로, 음성 신호에 에코 효과를 적용함.
B. Manipulation Attacks vs. Adversarial Attacks
Manipulation attacks은 탐지 시스템을 우회하고 악의적인 목적을 달성하려 한다는 점에서 adversarial attacks과 유사하지만 세 가지 주요 이점을 제공함.
- Simple Implementation: 머신러닝에 대한 전문 지식이 필요하지 않으며, 오디오 신호 처리에서 흔히 사용되는 기본적인 기법 적용만으로도 탐지 우회가 가능함.
- Computational Efficiency: adversarial attacks는 최적화 기반 기법을 사용하여 탐지 시스템을 우회할 수 있는 adversarial sample을 생성해야 하므로 계산 비용이 매우 크지만, manipulation attacks는 간단한 신호 처리 기법을 적용하는 방식이므로 빠르고 쉽게 오디오 딥페이크에 적용이 가능함.
- No Prior Knowledge Required: 전통적인 adversarial attacks은 대상 모델에 대한 완전한 정보를 필요로 하는 반면, manipulation attacks는 탐지 모델에 대한 사전 지식 없이도 수행할 수 있으며 실제 환경에서 쉽게 적용 가능함.
3. Motivation
일반적인 기법인 volume control, fadeing, noise injection을 적용하여 딥페이크 샘플을 manipulate하여 테스트를 진행함. 기존 탐지 모델들은 조작된 샘플과 실제 샘플 간 특징 분포 차이가 감소하면서 탐지 성능이 크게 저하됨. 근본적인 이유는 다음과 같음.
- 기존 탐지 방법들은 오디오에 적용될 수 있는 manipulation을 고려하지 않음.
- 기존 방법들은 대부분 전통적인 지도 학습을 기반으로 훈련되었기 때문에, 특정 학습 데이터에 최적화됨.
4. CLAD Design
A. Overview
1. Pre-training
contrastive learning 방식을 통해 견고한 encoder를 학습하여 feature representative을 생성하는 것을 목표함. 이를 위해, 입력 데이터에 무작위로 다양한 manipulations을 적용하여 두 개의 조작된 샘플을 생성함. 동일한 오디오에서 생성된 증강 샘플들은 ‘positive pairs’으로 간주되고, 서로 다른 오디오에서 생성된 샘플들은 ‘negative pairs’으로 간주됨. encoder는 positive pairs에 대해서는 유사한 feature을 생성하도록, negative pairs에 대해서는 서로 다른 feature 을 생성하도록 학습됨.
Contrastive learning 강화를 위해, queue 메커니즘 [MoCo]을 활용하여 이전 negative 샘플들을 저장하여 사용함. encoder가 출력한 feature과 queue에 저장된 negative 샘플을 활용하여 contrastive loss을 계산함. 추가적으로, length loss을 도입하여 실제 샘플의 feature이 보다 밀집되도록 유도하여, downstream 성능을 향상시킴. 최종적인 Pre-training loss function는 다음과 같이 정의됨.
2. Downstream Training
Pre-trained encoder위에 linear classifier를 추가한 뒤, labeled 데이터셋을 사용하여 최종 탐지 모델을 훈련함. CLAD는 특정한 encoder 구조를 강제하지 않음. 대부분의 딥러닝 기반 end-to-end 탐지 모델이 기존 classification head를 제거하고 encoder로 사용할 수 있듯이 CLAD 또한 plug-and-play 방식으로 활용 가능함.
B. Contrastive Learning
이전 오디오 분야에서 사용된 contrastive learning 기법은 주로 SimCLR 프레임워크에 의존했으나, 우리는 MoCo 프레임워크를 선택함. MoCo는 음성 샘플을 저장하는 queue를 유지하여 더 많은 negative 샘플을 negative pair로 활용할 수 있다는 장점이 있음.
Moco 프레임워크는 query encoder Encq와 key encoder Enck로 구성되며, 이 두 encoder는 동일한 구조를 가지며, Encq의 파라미터를 사용하여 Enck의 파라미터를 부드럽게 업데이트하는 방식을 따름. 인코더는 입력 오디오의 서로 다른 augmentation 버전을 받아 각각의 특징 표현 q와 k를 생성함. 여기서 증강에는 앞에서 언급한 모든 manipulations이 포함되며, 훈련 중 무작위로 적용됨.
무작위 augmentation은 효율적인 학습이 안될 수 있지않나..?
Contrastive loss의 목표는 feature representative k가 queue에 있는 negative 샘플보다 feature representative q와 최대한 가깝도록 만드는 것임.
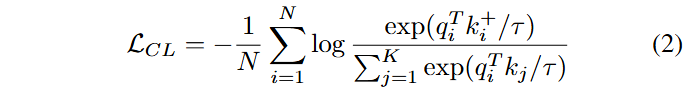
- N: batch size
- K: size of the negative samle queue
- τ: temperature parameter
- exp: consine similarity
- qi, k+i: feature q and feature k of the i-th sample in the batch
- kj: feature k of the j-th sample in the negative sample queue
Contrastive loss 계산 이후, query encoder의 파라미터는 gradient descent를 통해 업데이트되는 반면, key encoder의 파라미터는 momentum update 방식을 사용함.
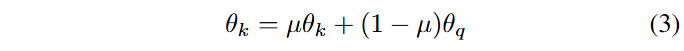
- θk, θq: parameters of the key encoder and the query encoder
- μ: momentum parameter
마지막으로, queue 업데이트 과정이 수행됨. 즉, 배치에서 생성된 feature k를 enqueue하고, 가장 오래된 샘플을 dequeue하여 최신 샘플만 유지함.
C. Length Loss
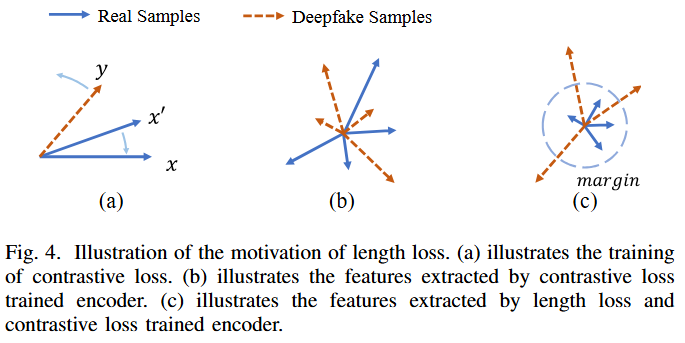
- 4(a): contrastive loss를 cosine similarity에만 의존하여 계산하면, 모델은 같은 소스에서 증강된 오디오 샘플 간의 feature vector 각도를 최소화하고, 다른 오디오 샘플 간의 각도를 증가시키는 방식으로만 학습됨.
- 4(b): 즉, 모델이 추출한 feature vector가 분산된 상태로 유지되며, 효과적인 clustering을 하지 못함. 실제 음성 샘플들은 서로 높은 유사성을 가지는 경향이 있지만, 다양한 알고리즘으로 생성된 합성 음성은 효과적으로 clustering되지 못함.
- 4(c): feature vector의 length 정보를 이용하는 length loss를 도입함. 실제 음성의 feature vector 길이를 줄이고, 오디오 딥페이크의 feature vector 길이는 증가시키도록 학습함.
Length loss는 encoder가 실제 음성 샘플에 대해서는 더 짧은 feature vector를 생성하고, 오디오 딥페이크에 대해서는 더 긴 feature vector를 생성하도록 유도함. 이는 실제 음성이 서로 더 유사한 feature를 가지는 경향이 있으며, 다양한 알고리즘으로 생성된 딥페이크는 상이한 feature를 가진다는 점을 반영한 것임.
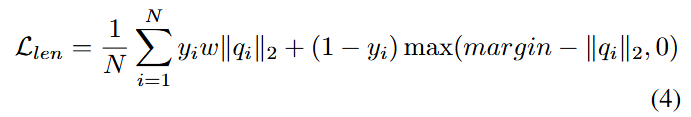
- N: batch size
- qi: feature of the i-th sample in the batch extracted by encode Encq
- yi: label of the sample
- w: weight factor to assign different levels of importance to the different classes, since the audio deepfake
detection dataset might be highly unbalanced. - margin: margin used to control the degree of separation between the real audios and audio deepfakes
결과적으로, contrastive loss와 length loss의 결합을 통해 방향과 크기를 모두 고려하는 feature 학습이 가능함.
- Contrastive loss은 feature vector의 directionality에 초점을 맞춤.
- Length loss은 feature vector의 magnitude를 조절함.
D. Downstream Training
Contrastive loss와 length loss를 활용하여 encoder 학습 후, 이를 linear layer와 결합하여 cross-entropy loss를 최소화 하는 방향으로 downstraem task를 수행함.
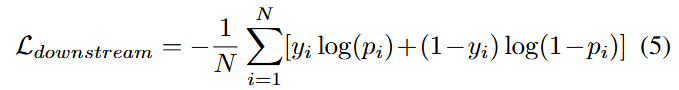
- N: batch size
- yi: label
- pi: predicted probability of being real for the i-th sample in the batch
5. Experimental Results
A. Experimental Settings
Baseline 모델로 공식 구현 코드 및 pre-trained weights가 공개되어있는 RawNet2, AASIST, Res-TSSDNet, SAMO를 선정함. 데이터셋으로는 ASVspoof 2019의 Logical Access (LA) 부분을 사용함. 사용된 metrics는 다음과 같음.
- False Acceptance Rate (FAR): 딥페이크를 실제로 잘못 분류한 비율로 manipulation attacks의 성공률을 측정하는 핵심 지표로 활용됨.
- False Rejection Rate (FRR): 실제를 딥페이크로 잘못 분류한 비율.
- F1 Score: precision와recall의 조화 평균.
- Equal Error Rate (EER): Detection Error Tradeoff (DET)에서 FAR과 FRR이 같아지는 지점.
threshold가 필요한 FAR, FRR, F1 Score에는 원본 데이터에서 EER을 도출하는 threshold를 사용함. 즉, 여기서는 FAR이 원본 데이터에서 EER과 동일한 값이 됨.
B. Manipulation Attacks Results
• RQ1: manipulation attacks은 널리 사용되는 오디오 딥페이크 탐지 시스템의 성능을 어떻게 저하시키는지.
• RQ2: CLAD 모델은 manipulation attacks이 존재하는 환경에서 오디오 딥페이크를 얼마나 효과적으로 탐지할 수 있는지.
• RQ3: contrastive learning 또는 length loss을 제거하면 CLAD 모델의 성능에 어떤 영향을 미치는지.
• RQ4: CLAD 모델은 이전에 학습되지 않은 unknown manipulations에 직면했을 때 성능이 어떻게 변하는지.
1. RQ1
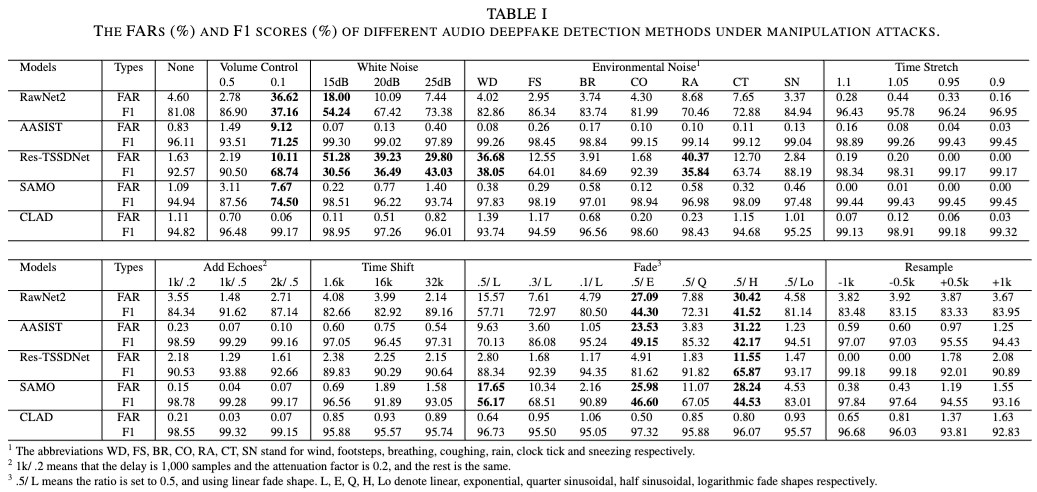
Manipulation attacks 기법이 baseline 모델 성능에 미치는 영향을 평가함.
- None: 모든 baseline 모델들은 우수한 탐지 성능을 보임.
- VC: 전반적인 모델 성능을 크게 저하시킴. VC coefficient를 0.1로 설정시, 모든 모델들에서 FAR이 상승함.
- WN & EN: RawNet2는 WN에 매우 취약하며, Res-TSSDNet은 WN, WD, RA에서 심각한 성능 저하가 발생함. 반면, AASIST와 SAMO는 noise가 포함된 샘플을 오히려 딥페이크로 더 잘 탐지하는 현상 발생.
- TS: 모델 성능에 큰 영향을 미치지 않음. 이는 time stretching 변환 과정에서 발생하는 인공적인 artifacts 때문으로 추정됨.
- SF & EC: 모델 성능에 큰 영향을 미치지 않음.
- FD: half sinusoidal fading을 적용했을 때, 모든 모델에서 성능 저하가 발생함.
- RS: 모델 성능에 큰 영향을 미치지 않음.
Manipulation attacks에 대한 CLAD의 견고성을 확인함.
- None: CLAD의 FAR은 0.83%에서 1.11%로 약간 증가함.
- WN & EN: CLAD가 압도적으로 강함.
- VC & FD: CLAD가 RawNet2 및 AASIST보다 훨씬 낮은 FAR 유지함.
- Combination Attacks: CLAD는 단일 조작 공격보다 복합 조작 공격에서도 더 낮은 FAR을 유지함.

None 원본 데이터에서는 실제와 딥페이크 샘플의 점수 분포가 뚜렷하나, manipulation attacks 적용 후에는 딥페이크 샘플의 점수 분포가 실제 분포로 이동함. 원래 threshold로 분류할 경우 FAR이 크게 증가함.
여러 manipulation attacks를 조합하여, baseline 모델 성능을 평가함.
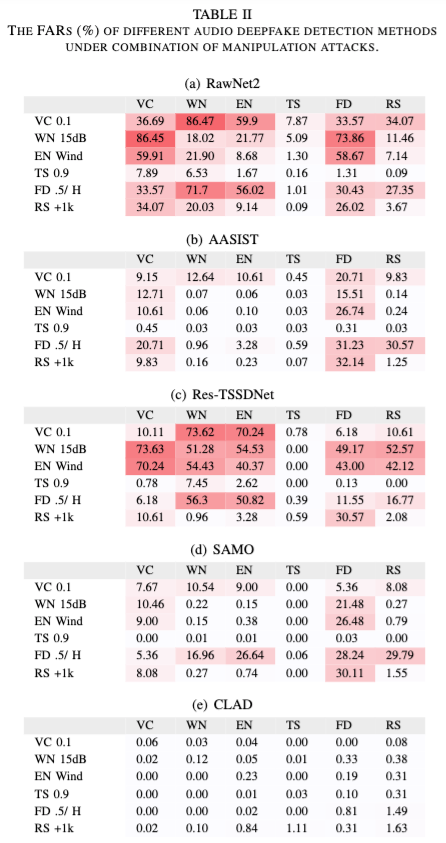
RawNet2와 Res-TSSDNet의 경우 조합된 attack에서 FAR이 급증함. 반면, AASIST와 SAMO의 경우 조합된 attack에도 FAR이 심각하게 증가하지는 않음.
결론적으로, 모든 baseline 모델들이 manipulation attacks에 취약함을 확인함. 특히, VC, WN, EN, FD가 FAR를 크게 증가시키는 기법이며, RawNet2와 Res-TSSDNet은 조합된 attacks에도 탐지 성능이 크게 감소됨. AASIST와 SAMO의 경우는 일부 manipulation attacks은 잘 탐지하지만, 여전히 취약점은 존재함.
2. RQ2 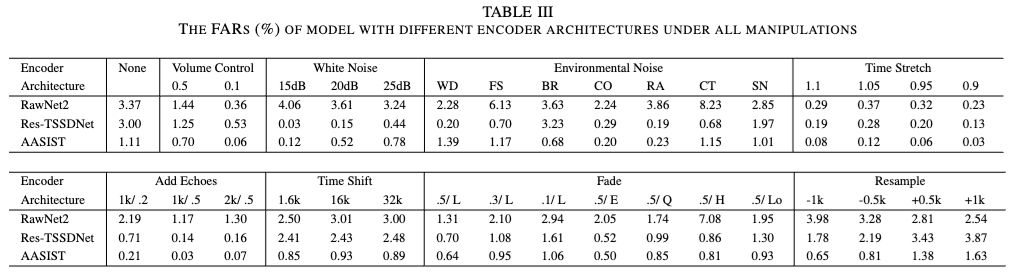
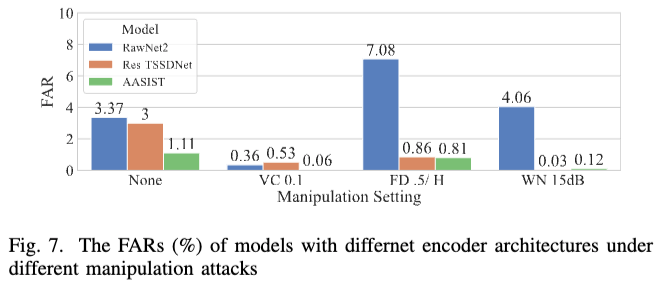
CLAD의 성능이 encoder 구조에 따라 달라지는지 평가하기 위해 baseline 모델들을 encoder로 교체하였으며, 본 연구에서는 ASSIST를 encoder로 선택함. 교체된 encoder로 학습된 CLAD는 모두 원본 baseline 모델들보다 manipulation attacks에서 더 높은 성능을 보임. CLAD는 특정 encoder 구조에 종속되지 않으며 기존 모델의 견고성을 전반적으로 향상시키는 역할을 함.
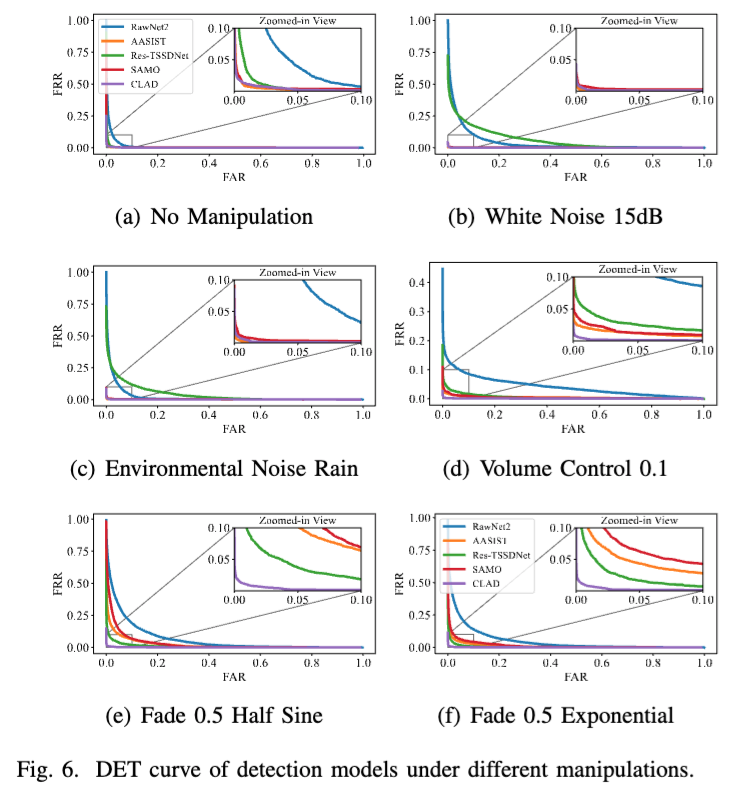
좌하단에 위치한 곡선이 탐지 성능이 더 좋은 모델을 의미함. CLAD는 consistently 우수한 성능을 유지, 반면 베이스라인 모델들은 특정 manipulation attack에서 탐지 성능이 급격히 저하됨.
3. RQ3
- Vanila: Baseline 모델과 다르게, 모든 manipulation 기법을 데이터 augmentation으로 활용하여 학습됨.
- CL: length loss 없이 contrastive learning만 적용된 모델.
- LL: Vanilla 모델에서 추가적인 loss function로 length loss을 적용한 모델.
- CLAD: 제안된 최종 모델.
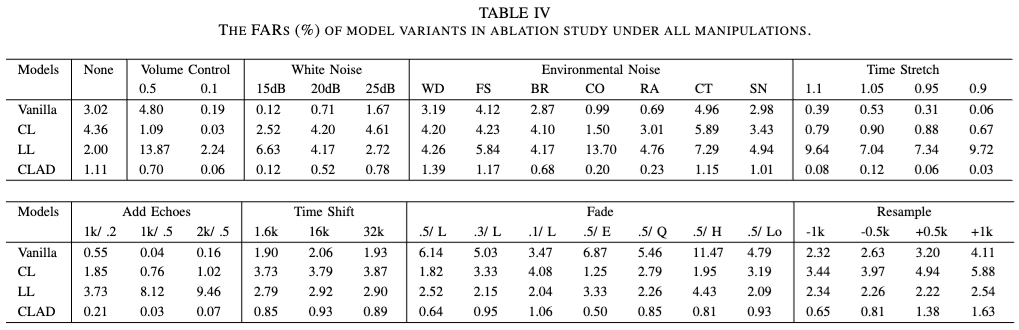
Contrastive learning은 manipulation attacks에 대한 견고성 향상에 매우 효과적임. Vanilla 및 LL 모델은 FD & VC에서 FAR이 크게 증가함. 이는 모든 manipulation 기법을 데이터 augmentatinon으로 활용하여 학습했음에도 불구하고, 전통적인 지도 학습이 다양한 manipulation을 효과적으로 처리하는 데 한계를 가짐을 의미함.
Length loss는 실제 오디오의 feature을 더 밀집된 형태로 학습하도록 유도하여, downstream 학습을 쉽게 만듦. 다양한 manipulation attacks에서도 동일한 패턴을 보이며, length loss가 모델 성능을 전반적으로 향상시키는 역할을 함. length loss는 feature vector의 길이를 활용하여, contrastive learning과 상호보완적인 효과를 가짐.
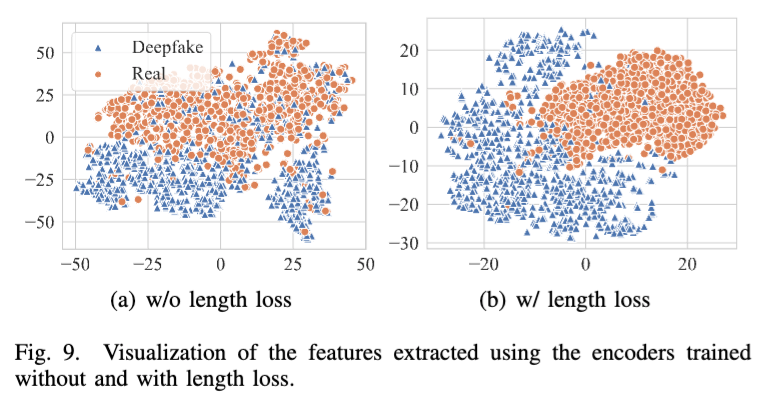
Encoder가 추출한 feature vector를 시각화하자, length loss를 적용한 모델이 더 밀집된 feature vector를 생성함.
4. RQ4
본 연구에서 8가지 manipulation methods을 실험하였으며, 이를 기반으로 각각 하나의 기법을 제외하고 학습된 8개의 CLAD 모델을 훈련함. column은 해당 기법을 제외하고 학습된 모델, row는 모델이 탐지해야하는 새로운 attacks를 의미함.
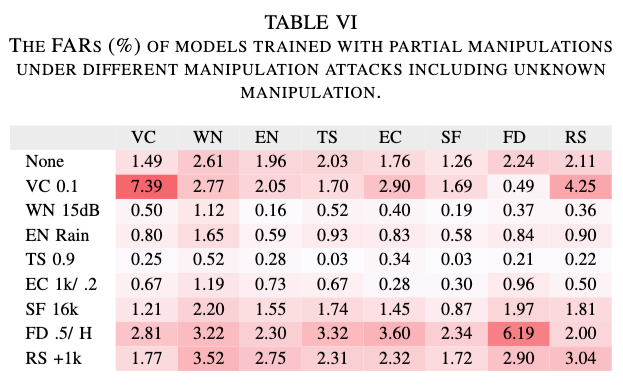
VC와 FD 같은 특정 attacks이 포함되지 않고 학습된 모델들은 높은 FAR를 기록함. VC와 FD가 탐지를 우회하는 데 매우 효과적인 기법임을 의미함. 반면, 다른 조작 공격은 모델의 탐지 성능에 큰 영향을 미치지 않음. CLAD는 기존 baseline 모델보다 미지의 manipulation attacks에 대해 더 강력한 성능을 보임.
6. Key Findings
- Manipulation attacks는 딥페이크 탐지 모델에 심각한 위협이 됨.
- 특히 VC과 FD가 탐지를 우회하는 데 가장 효과적인 기법임.
- CLAD는 Manipulation attacks에 대한 모델의 견고성을 크게 향상시킴.
- 기존 탐지 모델과 쉽게 통합 가능한 Plug-and-Play 방식으로 활용 가능함.
- Contrastive learning과 length loss는 CLAD의 핵심 요소임.
- Contrastive learning은 조작 공격에 대한 일관된 탐지 성능을 제공함.
- Length loss는 contrastive learning을 보완하여 추가적인 성능 향상을 유도함.
- CLAD는 unknown manipulation attacks에서도 강력한 성능을 보임.
- VC와 FD과 같은 강력한 manipulation attacks에서도, 기존 baseline 모델보다 FAR이 크게 낮음.
7. Related Work
8. Discussion
A. Intuitive Defense
Manipulation attacks에 대한 직관적인 방어 기법 중 하나는 noise injection을 방어하기 위한 denoising 기법임. 그러나 사전 실험에서는 filter를 적용했을 때, 만족스러운 성능을 얻지 못했음. 따라 최신 음성 향상 기법은 탐지 성능을 개선할 가능성이 있음. 그러나, 음성 향상 과정에서 발생하는 인공적인 feature이 탐지 모델의 오탐을 유발할 가능성이 있어 우려됨.
B. Diverse Datasets
기존 연구 저자들이 제공한 매개변수를 사용한 baseline 모델을 사용하기 위해, 평가 데이터셋이 ASVspoof 2019에 제한됨.
9. Conclusion
본 논문은 기존 오디오 딥페이크 탐지 시스템이 manipulation attacks에 취약하다는 점을 밝히고, 해결을 위해 contrastive learning과 length loss를 결합한 CLAD를 개발함. CLAD는 기존 모델들보다 훨씬 강건한 탐지 성능을 달성함.
'논문 리뷰 > Research Paper' 카테고리의 다른 글
| Contrastive Clustering (0) | 2025.03.05 |
|---|---|
| DRL for MultiagentSystems: A Review of Challenges,Solutions, and Applications (0) | 2021.08.18 |
댓글