Main Paper https://arxiv.org/pdf/1605.06676.pdf
Learning to Communicate with Deep Multi-Agent Reinforcement Learning
Abstract
We consider the problem of multiple agents sensing and acting in environments with the goal of maximising their shared utility. In these environments, agents must learn communication protocols in order to share information that is needed to solve the tasks. By embracing deep neural networks, we are able to demonstrate end-to-end learning of protocols in complex environments inspired by communication riddles and multi-agent computer vision problems with partial observability.
/* MDRL에서 agent 간에 공유되는 효용을 극대화 하기 위해, env를 감지하고 행동하는 multiple agent의 문제를 고려해야만 하므로, 정보 공유를 위한 통신 프로토콜이 필요하다. 복잡한 multi-agent env에서의 patial observability를, DNN을 수용하여 end-to-end agent 간의 학습을 해결한다. */
Introduction
The tasks that we consider are fully cooperative, partially observable, sequential multi-agent decision making problems. While no agent can observe the underlying Markov state, each agent receives a private observation correlated with that state.
/* 이 논문에서는 partially observable, sequential multi-agent decision making하는 fully cooperative problem에 대해서 알고리즘을 제시한다. 모든 agent는 Markov state를 관찰 불가능하고, 각 agent는 해당 state에 관련된 private obeservation만을 받는다. */
In addition to taking actions that affect the environment, each agent can also communicate with its fellow agents via a discrete limited-bandwidth channel. Due to the partial observability and limited channel capacity, the agents must discover a communication protocol that enables them to coordinate their behaviour and solve the task.
*/ env에 영향을 미치는 action을 취하는 것 외에도, 각 agent는 별도의 channel capacity를 통해 다른 agent와 communicate 가능하다. partial observability와 limited channel capacity를 통해, agent는 action을 조정한다. 작업을 해결 가능한 communication protocol을 찾아야 한다. */
Setting
RL 문제를 multi-agent와 parital observability 관점에서 고려한다.
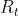
(R_t): 모든 agent가 최대화 하려는 동일한 discounted sum of rewards
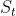
(S_t): 모든 agent가 관찰 불가능한 기본 Markov state
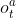
(o^a_t): 각 agent가 받는 private observation, S_t와 관련됨
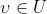
(u): 각 time-step에서 agent가 env에 영향을 미치는 env action
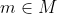
(m): 각 time-step에서 다른 agent로부터 관찰되는 env나 reward에 영향을 주지 않는 communication action
partial observability multi-agent일 때, agent가 communication할 incentive를 가질 수 있다. 사전에 communication protocol이 제공되지 않으므로 agent에게는 이러한 protocol이 필요하다.
We focus on settings with centralised learning but decentralised execution. In other words, communication between agents is not restricted during learning, which is performed by a centralised algorithm; however, during execution of the learned policies, the agents can communicate only via the limited-bandwidth channel.
/* centralised learning이지만 decenralised execution을 한다는 것에 중점을 두어야 한다. 즉 agent 간의 communication은 centralised algorithm으로 수행되는 learning동안 제한되지 않는다. 그러나 learned policy를 execute하는 동안 agent는 limited-bandwidth channel을 통해서만 소통할 수 있다. */
centralised planning과 decentralised execution은 multi-agent planning의 표준 패러다임이다.
Methods
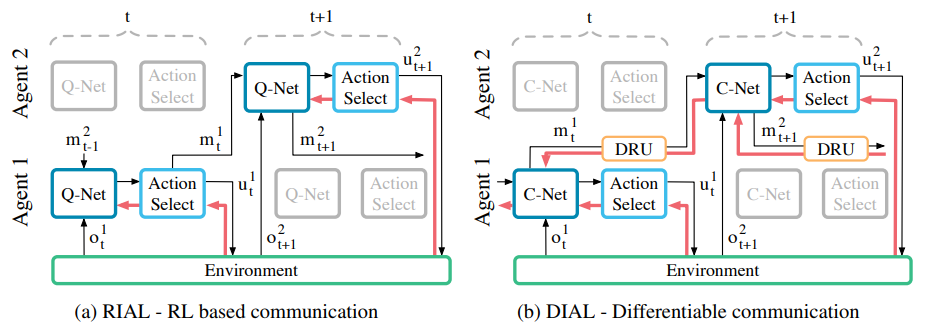
RIAL (Reinforced Inter-Agent Learning) concept
: uses deep Q-learning with a recurrent network to address partial observability.
/* partial observability를 해결하기 위해, recurrent network과 함께 deep Q-learning을 사용한다. (DRQN) */
In one variant of this approach, which we refer to as independent Q-learning, the agents each learn their own network parameters, treating the other agents as part of the environment.
/* Independent Q-learning이라고 하는 변형으로, agent는 자신만의 network paramenter를 학습하여 다른 agent를 env의 일부로만 취급하고 action한다. */
Another variant trains a single network whose parameters are shared among all agents. Execution remains decentralised, at which point they receive different observations leading to different behaviour.
/* 또 다른 변형으로는, 모든 agent 간에 공유되는 parameter의 single-network를 훈련시킨다. execution은 decentralised하게 유지되며 이 시점에서 다른 행동으로 이어지는 다른 observation을 받는다 . */
RIAL process
RIAL combine DRQN with independent Q-learning for action and communication selection. Each agent’s Q-network represents Qa(o^a_t, m^a′_t-1 , h^a_t-1 , u^a), which conditions on that agent’s individual hidden state and observation.
/* action과 communication selection을 위해 DRQN을 independent Q-learning과 결합한다. 각 agent의 Q-network는
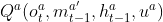
를 나타내며, 각 agent의 hidden state와 observation에 조건한다. */
=> agent가 partially observable하게 얻는 state, 다른 agent의 action, 각 agent의 hidden state, agent가 취하는 env로의 action의 parameters로 Q-network가 표현된다.
To avoid needing a network with |U||M| outputs, we split the network into Q^a_u andQ^a_m, the Q-values for the environment and communication actions, respectively. the action selector separately picks u^a_t and m^a_t from Q_u and Q_m, using an ε-greedy policy. Hence, the network requires only |U | + |M | outputs and action selection requires maximising over U and then over M , but not maximising over U × M.
/* |U||M| 의 출력을 동시에 필요로 하는 network가 필요하지 않도록, network를 각각 env, communication action에 대한 Q-value인 Q_au와 Q_am으로 분할했다. action selector는 e-greedy policy를 이용하여 Q_u와 Q_m에서 u^a_t와 m^a_t를 별도로 선택한다. 따라서 network에는 |U| 와 |M| 각각의 출력을 최대화 하는 방향으로 action select가 진행되어야 한다. */
=> 결국 각 agent는 다른 agent의 action을 고려하는 network와 env와의 action을 고려하는 network를 각각 최대화하는 방향으로 action을 선택한다. 이때 action selector는 e-greedy하게 각 network에서의 action을 선택한다.
Q_u와 Q_m은 모두 DQN을 사용하여 훈련되고 다음의 두가지 특성을 지닌다.
First, we disable experience replay to account for the non-stationarity that occurs when multiple agents learn concurrently, as it can render experience obsolete and misleading.
/*1. multi-agent가 동시에 learning할 때, 발생하는 non-stationary를 고려하여 오류로 취급되는 experience replay를 제거할 수 있다. */
=> 여러 agents들이 동시에 학습할 경우, 다른 agent에게 env가 non-stationary하게 바뀌는 것처럼 다가오기 때문에, experience replay를 제거한다.
Second, to account for partial observability, we feed in the actions u and m taken by each agent as inputs on the next time-step.
/* 2. partial observability를 고려하여, 각 agent가 취한 action u와 m을 다음 time-step의 입력으로 제공한다. */
=> 아래 그림에서 처럼 agent가 선택한 action u,m를 서로에게 input으로 제공한다.
아래 그림은 agent와 env간에 정보가 흐르는 flow, action, u^a_t 및 m^a_t를 생성하기 위해 action selector가 Q-value를 처리하는 방법을 보여준다. 이 접근 방식은 agent를 독립적인 network로 취급하므로, problem setting이 centralised 할지라도 learning 단계는 decentralised하다.
=> 결과적으로 agent는 learning 시에, decentralised execution과 같이 취급된다.
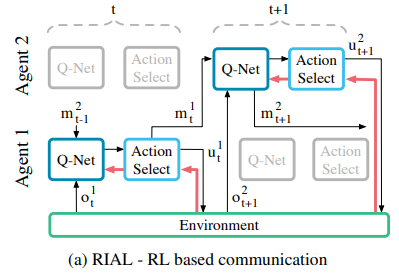
all Q-values are fed to the action selector, which selects both environment and communication actions. Gradients, shown in red, are computed using DQN for the selected action and flow only through the Q-network of a single agent.
/* 모든 Q-value는 env, communication actions를 모두 선택하는 action selector에게 제공된다. 빨간색으로 표시된 선인 gradient는 선택한 action에 대해 DQN을 사용하여 계산되고, single-agent의 Q-network를 통해서만 흐른다. */
+ Parameter Sharing
: RIAL can be extended to take advantage of the opportunity for centralised learning by sharing parameters among the agents. This variation learns only one network, which is used by all agents. However, the agents can still behave differently because they receive different observations and thus evolve different hidden states.
/* agent 간 parameter를 공유하여 centralised learning을 활용하도록 RIAL를 확장할 수 있다. 이 변형은 모든 agent가 사용하는 하나의 network만 학습한다. 그러나 agent는 서로 다른 observation을 받고, 다른 hidden state를 진화시키기 때문에 여전히 다르게 행동한다. */
In addition, each agent receives its own index a as input, allowing them to specialise. The rich representations in deep Q-networks can facilitate the learning of a common policy while also allowing for specialisation. Parameter sharing also dramatically reduces the number of parameters that must be learned, thereby speeding learning.
/* 또한 각 agent는 자신의 index를 입력으로 받아 특화될 수 있다. DQN의 풍부한 표현은 common policy 학습을 촉진하는 동시에 전문화를 허용 가능하다. parameter 공유는 학습해야하는 parameter 수를 크게 줄여 학습 속도 또한 높일 수 있다. */
parameter sharing에서 agent는 다음의 2가지 Q-function을 학습한다.
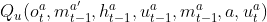
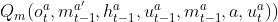
=> 기존 independent Q-learning에서의 각자 학습했던 아래의 Q-function에, shared parameters를 추가하여 Q-function 학습과 동시에 common policy를 학습할 수 있다.
During decentralised execution, each agent uses its own copy of the learned network, evolving its own hidden state, selecting its own actions, and communicating with other agents only through the communication channel.
/* decentralised execution 중에는, 각 agent는 learned network의 자체 copy를 사용하여 own hidden state를 발전시키고, own action을 선택하며, communication channel를 통해서만 다른 agent와 통신한다. */
DIAL (Differentiable Inter-Agent Learning) concept
: is based on the insight that centralised learning affords more opportunities to improve learning than just parameter sharing. In particular, while RIAL is end-to-end trainable within an agent, it is not end-to-end trainable across agents, i.e., no gradients are passed between agents.
/* centralised learning이 parameter sharing보다 학습을 개선할 수 있다는 insight를 기반으로 한다. 특히, RIAL은 agent 내에서 end-to-end 학습이 가능하지만, agent 간 end-to-end 학습은 불가능하다. 즉, agent간에 gradient가 전달되지 않는다. */
=> DIAL은 agent 간에 gradient가 전달되며 centralised learning이 가능하다.
While RIAL can share parameters among agents, it still does not take full advantage of centralised learning. In particular, the agents do not give each other feedback about their communication actions
/* RIAL은 agent 간에 parameters를 공유할 수 있지만, centralised learning을 활용하지 못하였다. 특히 agent는 communication action에 대해 서로 feedback을 제공하지 않는다. */
=> 즉, RIAL은 decentralised learning으로 진행되다싶이 하였으며, communication protocols를 학습하는데 중요한 feedback mechanism이 없다.
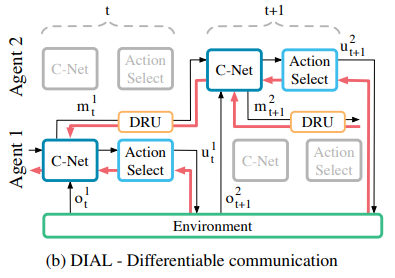
The second approach allows real-valued messages to pass between agents during centralised learning, thereby treating communication actions as bottleneck connections between agents. As a result, gradients can be pushed through the communication channel, yielding a system that is end-to-end trainable even across agents. During decentralised execution, real-valued messages are discretised and mapped to the discrete set of communication actions allowed by the task. Because DIAL passes gradients from agent to agent, it is an inherently deep learning approach.
/* centralised learning 중에 agent 간 real-valued 메시지를 전달할 수 있도록 하여, communication action을 agent 간 bottleneck connection으로 처리한다. 결과적으로 gradient가 통신 채널을 통해 전달되어, agent 간에도 end-to-end 교육이 가능한 시스템이 생성된다. decentralised execution 중에 real-value 메시지는 discrete되어, task에서 허용하는communication action 집합에 매핑된다. DIAL은 agent 간에 gradient를 전달하기 때문에 본질적으로 딥러닝 방법이다. */
=> DIAL은 centralised learning과 Q-network의 조합을 통해, 매개변수 공유 뿐만 아니라 communication channel을 통한 gradient push가 가능하다. 따라서 DIAL은 agent 간 end-to-end 학습이 가능하다. agent 간 gradient 이동은 풍부한 feedback을 제공하여 error를 통해 optimize하여 최적의 protocol를 찾을 수 있다.
DIAL process
during centralised learning, communication actions are replaced with direct connections between the output of one agent’s network and the input of another’s. Thus, while the task restricts communication to discrete messages, during learning the agents are free to send real-valued messages to each other.
/* centralised learning 동안, communication actions는 agent 끼리의 출력과 입력의 연결로 새롭게 대체된다. 따라서 task가 discrete messages로 communication을 제한하는 동안, agent는 학습할 때 서로에게 real-valued message를 자유롭게 보낼 수 있다. */
=> 이러한 message는 network activation과 같은 기능을 하고, channel을 따라 gradient를 전송 가능하므로 agent간 end-to-end backpropagation이 가능하다.
C-Net이라 부르는 network는 다음 2가지 distinct types of values를 출력한다.
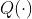
: action selector로 주어지는 env actions에 대한 Q-values
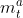
: action selectior를 우회하고 대신 discretise/regularise unit (DRU(m^a_t)에 의해 처리되는, 다른 agent에 대한 real-valued message
=> DRU는 centralised learning 중에 logistic function을 통해 regularise하고, decentralised execution 중에 Gausian noise를 통해 discreties한다. 결국 주어진 수식에 의해서 DRU(m^a_t)가 regularise 및 discreties 된다.
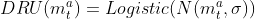
σ: channel noise의 standard deviation
The gradient chains for Qu, in RIAL and Q, in DIAL, are based on the DQN loss. Using this inter-agent gradient for training provides a richer training signal than the DQN loss for Qm in RIAL. While the DQN error is nonzero only for the selected message, the incoming gradient is a |m|-dimensional vector that can contain more information, here |m| is the length of m.
/* RIAL의 Q_u와 DIAL의 Q에 대한 gradient chain은 DQN loss를 기반으로 한다. learning 시에, DIAL에서 agent 간의 gradient를 이용하면, RIAL에서 Q_m에 대한 DQN loss보다 더 풍부한 backpropagated error를 제공한다. 만약 DQN loss가 0이 아니라면, incoming gradient는 더 많은 정보를 포함할 수 있는 |m|-차원 vector이다. (|m|: m의 길이)*/
=> RIAL보다 DIAL의 방식에서의 gradient가 더 많은 정보를 포함하므로 network에서 DQN loss를 최소화하기 위해 message를 조정하는데 필요한 error & trial이 줄어들고, 좀 더 빠르게 수렴할 수 있다. Hence, RIAL <<< DIAL
Code
'논문 리뷰 > MARL algorithm' 카테고리의 다른 글
| [CommNet] Learning Multi-agent Communication with Backpropagation (0) | 2022.07.29 |
|---|---|
| [RIAL & DIAL] Learning to Communicate with Deep Multi-Agent Reinforcement Learning (0) | 2022.07.26 |
| [Distributed W-Learning] Multi-Policy Optimization in Self-Organizing Systems (0) | 2022.07.20 |
| A survey on MADRL: from the perspective of challenges and applications (0) | 2021.08.17 |
| CommNet (learning communication, PG) (0) | 2021.07.12 |
| Multi-agent Intro (0) | 2021.07.06 |

댓글