2009 Third IEEE International Conference on Self-Adaptive and Self-Organizing Systems
Abstract
: 여러 policies의 최적화를 위해서는 large scale agent-based system에서의 multi-agent approach가 필요하다. agent가 operating env를 공유함에 따라, agent 간, policy 구현 간 상당한 종속성이 발생할 수 있다. 해당 논문에서는 agent heterogeneity, policy dependency, global 지식 부족이 발생하는 경우, 자체 최적화를 해결하기 위해 distributed W-learning(DWL)을 제안한다. DWL는 multiple policies에 대한 collaborative agent-based self-optimization 방식이고, single policy의 성능보다도 뛰어난 multiple policies을 얻을 수 있다.
Introduction
: 많은 large-scale system은 시간적, 공간적 범위와 우선 순위가 서로 다른 여러 충돌 목표에 대해 자체 최적화가 필요하고, 이러한 policy heterogeneity는 agent heterogeneity을 유발하여 self-organization에 필요한 coordination을 어렵게 만든다. DWL는 agent가 목표의 우선 순위를 존중하면서 목표에 대한 system 성능을 최적화하기 위해 서로 다른 수준의 cooperation에 참여할 수 있도록 한다. collaboration mechanism은 agent가 구현하는 policy와 무관하므로 heterogeneous agent 간 collaboration이 가능하다.
Multi-policy optimization
Policy characterisstic
: policy는 서로 다른 특성을 가질 수 있다. 또한 특성이 동일하더라도 서로 다른 관계를 가질 수 있다.
1. Spatial scope
: policy는 서로 다른 agent set에 배치될 수 있다. 즉, 다른 spatial scope를 가진다. spatial scope에서 policy는 local(single agent에 배포), regional(system의 agent subset에 배포), global(system의 모든 agent에 배포)일 수 있다.
2. Temporal scope
: policy는 서로 다른 시간에 활성화 될 수 있다. 즉, 다른 temporal scope를 가진다. temporal scope에서 policy는 산발적이거나 연속적일 수 있다.
3. Prioritiy scope
: policy는 system에 의해 서로 다른 중요도 수준을 가질 수 있다. 즉, 다른 우선순위를 가진다. 우선 순위는 낮음에서 높음으로 다양하다.

- multi-agent env에서 multi-policy optimization는 system 목표를 명시적으로 충족할 뿐만 아니라, agent & policy dependency와 heterogeneity의 의미도 해결해야 한다.
Agent dependency
: multi-agent system에서 agent의 성능은 다른 agent's action에 의해 직간접적으로 긍정 및 부정적인 영향을 받을 수 있다. system 내 모든 agent 간에 잠재적 dependency가 존재한다.
→ 따라서 agent는 실행할 action을 선택할 때, 자신의 직접적인 이익뿐만 아니라, neighbor agent에 대한 해당 action의 영향도 고려해야 한다.
Agent Heterogeneity
: agent가 heterogeneous하고 서로 다른 policy를 시행할 때, agent가 다른 agent의 요구를 고려하는 것은 어렵다. 다음은 heterogeneity의 원인들이다.
Difference in the agents' operating env and capabilities
: env에서 agent가 사용할 수 있는 state space와 action space가 모두 다르기 때문에, agent는 특정 state 혹은 action에 대한 공통적 해석을 가지지 못한다.
Different policies being deployed
: policy의 spatial, temporal scope가 다르기 때문에, 특정 시점에 서로 다른 policy set을 구현할 수 있다.

- agent A2는 policy p1 및 p2를 구현하는 데 필요하지만 neighbor agent 중 하나인 A1은 p1만 구현하고 다른 neighbor agent A3은 p2만 구현한다. 추가 다운스트림 이웃 A4는 자체 local policy p3만 구현한다.
→ agent의 state space, action space가 각각 다르고, 영향을 받는 policy가 매번 바뀌기 때문에 agent가 다른 agent의 요구를 고려하는 것은 어렵다.
Policy Dependency
: agent dependency와 agent heterogeneity는 policies 간에도 dependency를 유발할 수 있다. policy dependency는 DWL 설계를 통해 추후 해결한다.
→ agent는 action을 선택할 때, 자신의 policy를 구현하는데 가장 적합한 action을 고려해야할 뿐만 아니라, 그 행동이 다른 agent뿐만 아닌 agents' policies까지 고려해야만 한다.
Algorithm Requirements
1. agent가 자신의 optimal action 뿐만 아니라 다른 agent의 자신의 action에 대한 영향까지 학습할 수 있어야 한다.
: agent는 공유 env로 인한 dependency가 있으므로 mutual cooperation의 이점을 얻을 수 있다.
2. agent에 배포된 여러 policies를 동시에 처리할 수 있어야 한다.
: policy가 배포되는 공유 env로 인해 policy dependency가 있을 수 있기 때문이다.
3. local 학습 및 interaction만 가능하다.
: 어떤 agent도 전체 system에 대한 global view를 가지고 있지 않다.
Distributed W-learning
DWL overview
: agent가 neighbor action preference(collaborate)를 고려하도록 동기를 부여하기 위해, 각 agent와 자체 policies는 인접한 neighbors에 배포된 각 policies에 대해, neighbor N_i가 policy P_ik를 구현하도록 도와 달라는 "remote" policy를 구현한다. 이 policy는 policy P_ik가 neighbor N_i에 대한 reward를 받을 때마다 reward를 받는다.
→ remote policy를 사용하여 DWL은 heterogeneous agent, 즉 서로 다른 policy를 구현하고 서로 다른 state space 및 action space를 갖는 agent 간 cooperation을 가능하게 한다.
Definition of DWL
: DWL system은 다음으로 구성된다.

- 각 agent에 대한 각 policy는 Q-learning과 W-learning의 조합으로 구현된다. 각 state-action pair과 연결된 Q-value와 각 state와 연결된 W-value가 있다.
DWL algorithm

- 학습 과정에서 local action이 neighbor state에 미치는 영향을 학습하기 위해서는 각 time-step에서 neighbor's current states와 rewards에 대한 정보를 받아야 한다.
- 각 time-step에서 local 및 remote policy 모두 W-value로 action을 지정한다. inactive policy의 W-value는 0으로 지정한다.
1. agent는 local state와 local action으로 local policy에 대한 학습 프로세스를 시작한다.

- agent A_i's local policy만큼 반복
- A_i's state LP_il와 A_i's action로 Q-learning 초기화
- A_i's state LP_il로 W-learning 초기화
2. agent는 remote state와 local action으로 remote policy에 대한 학습 프로세스를 시작한다.

- N_i에 속한 neighbor agent A_j만큼 반복
- A_j's local policy만큼 반복
- A_i's local policy에 기여하는 A_j's policy를 policy set에 추가

- 위에서 추가한 policy set만큼 반복
- A_j's state RP_ijk와 A_i's action로 remote Q-learning 초기화
- A_j's state RP_ijk로 remote W-learning 초기화
- agent A2에 대한 DWL 지명 프로세스 한 단계를 보여준다.

1. local policies의 Q-value와 W-value를 구한다.

- local policy LP_i만큼 반복
- LP_il에 따른 state 선택 후, A_i env로부터 reward 획득
- Q(s_il-1, a_il-1) update, LP_il을 위해
- W(s_il-1) update
- max Q로 action a_il 지명, s_il을 위해
- W(s_il) 획득
2. remote policies의 Q-value와 W-value를 구한다.

- remote policy RP_ijk만큼 반복
- RP_ijk에 따른 state 선택 후, neighbor A_j env로부터 reward 획득
- Q(s_ijk-1, a_ijk-1) update, LP_il을 위해
- W(s_ijk-1) update
- max Q로 action a_ijk 지명, s_ijk을 위해
- W(s_ijk) 획득
3. W-value를 비교하여 winning action을 실행한다.

- local policy action nomination은 W-value 자체로 고려되는 반면, remote policy nomination에는 cooperation coefficient C(0 <= C <= 1)를 곱하여 agent가 neighbor action preference에 다양한 가중치를 부여할 수 있다.
- C=0, local agent가 non-cooperative하다는 것을 의미한다. 즉, action 선택 시 neighbors' performance를 고려하지 않는다.
- C=1이면, local agent가 fully-cooperative하다는 것을 의미한다.
- 해당 time-step에서 실행되는 action은 remote win W-values를 cooperation coefficient로 scaling 한 후, policy competition 중 highest W-value 값의 action이 실행된다. W_il은 A_i의 local policy에서 지정한 W-value이고, W_ijk는 A_i의 remote policy에서 지정한 W-value이다.
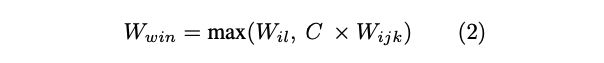
→ 최종적으로, local policy에서의 W-value와 remote policy에서의 W-value를 비교하여 실행할 action을 결정한다.
DWL results
: DWL performance를 baseline에 대해 평가하고, single policy와 multi-policy scenario performance를 비교한다.
(a), (b)는 각 GWO(opimizing global waiting time), PTO(prioritizing public transport vehicles) policy에서 single policy와 multi-policy의 비교를 보여준다. (c), (d)는 traffic load가 높을 때 측정한 경우를 보여준다.
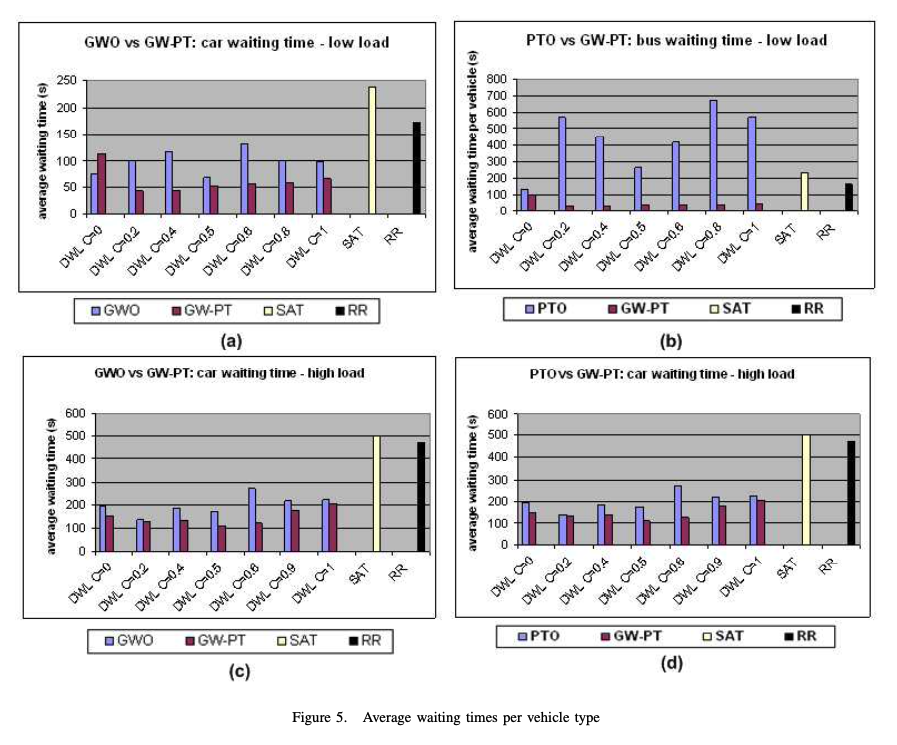
- density를 비교했을 때, GW-PT는 꾸준한 반면, PTO는 계속 증가했다.

- traffic load에서의 GW-PT scenario에서 버스의 평균 대기 시간이 자동차의 평균 대기 시간보다 낮음을 관찰했다. 따라서, DWL가 policy의 relative priorities를 존중할 수 있다는 결론을 내릴 수 있다.

→ DWL에서는 여러 policies를 동시에 배포할 수 있으므로 agent가 single-policy optimization보다 multi-policy optimization의 이점을 활용 가능하다. 또한 heterogeneous agents 간의 성능 향상 cooperation을 가능하게 하고, agent가 참여하는 cooperation 수준의 측면에서 flexibility를 허용할 수 있다.
DWL conclusion
: 해당 논문에서는 여러 agent에 대한 여러 policies에 대한 최적화를 동시에 가능하게 하여 agent가 서로 다른 수준의 cooperation에 참여할 수 있도록 하는 DWL를 제안한다. 해당 algorithm의 multi-policy를 동시에 실행할 수 있는 기능(multi-policy scenario가 single-policy scenario보다 우수하다)과 다양한 policies를 구현하는 agent 간의 cooperation을 가능하게 하는 기능(cooperative scenario가 non-cooperative보다 우수하다)으로 기존 baseline보다 성능이 향상된다. 또한 다양한 수준의 cooperation이 다양한 system load에 적합하다는 것을 관찰 가능하다.
'논문 리뷰 > MARL algorithm' 카테고리의 다른 글
| [DRON] Opponent Modeling in Deep Reinforcement Learning (0) | 2022.07.29 |
|---|---|
| [CommNet] Learning Multi-agent Communication with Backpropagation (0) | 2022.07.29 |
| [RIAL & DIAL] Learning to Communicate with Deep Multi-Agent Reinforcement Learning (0) | 2022.07.26 |
| A survey on MADRL: from the perspective of challenges and applications (0) | 2021.08.17 |
| CommNet (learning communication, PG) (0) | 2021.07.12 |
| RIAL & DIAL (learning communication, VB) (0) | 2021.07.07 |
댓글