29th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain
Abstract
: env에 영향을 주는 action과 agent간의 action을 고려한 두개의 network를 각각 최대화하는 RIAL & DIAL의 communication method와 다르게, CommNet에서는 communication은 policy와 동시에 학습된다. 해당 논문에서는 fully cooperative tasks에 대해서 continuous communication을 사용하는 simple neural model를 탐구한다. 방법의 적용으로, non-communicative agents & baseline보다 agent가 서로 communicate하는 방법을 배울 시에 성능적 향상을 제공함을 볼 수 있다.
Introduction
: CommNet의 간단한 structure를 보자면, 처음 agent는 communication channel을 통해서 다른 모든 agent의 state에 대한 feature vector를 가지게 된다. 그 후 communication step을 거치며, agent 마다의 module로 feature vector들에 대한 처리를 통해 다음 step으로 넘겨준다. 이 communication step이 쌓여서 CommNet을 구성하게 된다. 명확한 구조는 뒤에서 상세히 살펴본다.
- 각 agent가 own controller를 가지는 관점과 모든 agent를 통제하는 super agent J의 관점에 차이는 없지만 후자로 보면, 각 agent가 다른 agent들의 state를 받아서 각 action을 출력하는 large feed-forward network라고 볼 수 있다.
Communication Model
: given time-step t에서 action probability에 대한 distribution을 계산하는데 사용되는 모델을 설명한다.
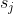
: agent j 관점에서의 env에 대한 state-view

: all agent's state-view의 concatnation, controller input

Φ: mapping controller a = Φ(s), single controller Φ는 agent 간의 communication과 각 agent의 개별 controller 모두를 포괄한다.

: discrete actions의 concatnation, controller output

: network communication steps 개수
Controller Structure
: multi-layer neural network form의 module f^i로 구축된 controller Φ architecture이다.

Single agent j module
: 각 f^i module은 각 agent j에 대해 h^i_j와 c^i_j를 input vector로 h^{i+1}_j output vector를 생성한다. 이 때, c^i_j는 communication, h^i_j는 hidden state이다.

ith communication step
: model main body는 concatenated vector h^0를 input vector로 받아 output vector를 생성한다.


Commnet model
: f^i가 non-linearity σ를 가지는 single linear layer인 경우, 아래의 식을 통해

아래의 layer가 있는 feedforward network로 model이 보여질 수 있다.

- 이 때, T^i는 block form을 취한다.

- agent 수가 다를 수 있기 때문에 T array의 크기가 동적으로 조정된다. 이는 communication agent 개수에 의해 communication vector를 재조정하는 equation(2)에 normalizing factor J-1이 있는 이유이다. 또한 T^i는 input vector element의 순서와 상관없이 같은 output을 생성하는 permutation invariant하므로 agent의 순서는 중요하지 않다.
1) at model first layer
: 아래의 encoder function이 사용된다. state-view s_j를 input으로 하여 feature vector h^0_j를 output한다. encoder function은 problem independent하지만 대부분의 task에서는 single layer neural network이다. 명시되지 않는 이상, 초기 모든 agent j에서 c^0_j=0이다.

2) at output of model
: 아래의 decoder function은 action space에 대한 distribution을 output하는데 사용된다. 따라 q(h^K_j)는 single layer network form을 취하고 softmax를 거친다. discrete action을 생성하기 위해, a_j ~ q(h^K_j) distribution에서 sampling한다.

→ 모든 혹은 주위 agents의 state를 가져와 encoder에 입력한다. hidden state를 학습시키는 communication step을 반복하여 진행하여 나온 hidden state에 따라 action distribution을 출력한다. communication과 policy를 동시에 학습한다.
Model extensions
Local connectivity
: 위에서의 broadcast framework의 대안으로는 certain range에서 다른 agent와 communicate 할 수 있도록 한다. 그러면 equtaion(2)는 다음과 같이 변환된다. 이 때, N(j)는 agent j의 communication range 내에 존재하는 agent set이다.

Skip connections
: 일부 작업의 경우, first layer 이후의 communication step에 대한 input으로 encoding h^0_j를 사용하는 것이 더 유용하다. 따라서 i step의 agent j에서 다음을 수행한다. h^0_j는 r(s_j)의 encoder function으로 초기 feature vector이다.

Temporal recurrence
: Eqn의 communication step i를 단순히 대체함으로써 network가 RNN이 되게 할 수 있다. (1)과 (2)는 모든 time-step t에 대해 동일한 module f^t를 사용한다. 모든 time-step에서 actions는 q(h^t_j)에서 sampling된다. agent는 언제든지 swarm을 떠나거나 합류할 수 있다는 것은 유의해야 한다. 만약 f^t가 single layer network일 경우, 우리는 서로 communicate하는 plain RNN을 얻을 수 있다. 추후 실험에서는 RNN 대신 LSTM를 f^t module로 사용한다.
→ extensions을 통해, 다양한 multi-agent env에 적용이 가능하며 일부 성능향상에도 도움을 준다.
CommNet results
- Traffic junction에서 CommNet은 다른 model에 비해 뛰어난 성능을 보였다. 이 때, module f() type에 따라서도 성능차이가 존재했다.

Conclusion
: CommNet을 통해 동적으로 변화하는 agent set 간의 지속적인 communication을 학습할 수 있는 controller를 학습할 수 있다. models without communication, fully-connected model, discrete communication model과의 비교를 통해 broadcast channel의 단순성에도 불구하고 agent간에 의미있는 정보를 전달했음을 알 수 있다.
댓글