Abstract
: Q-learning은 env의 non-stationary로 인한 어려움과 multi-agent domain에서 agent 수에 비례하는 variance 증가로 인한 어려움을 겪는다. 이를 해결하기 위해, 다른 agent의 action policy를 고려하고 multi-agent coordination이 필요한 policy를 학습할 수 있는 actor-critic method를 제시한다. 또한 보다 각 agent에 대한 policy ensemble을 활용하는 method 또한 도입한다.
Introduction
: Q-learning에서의 non-stationary env는 학습 안정성 문제와 replay buffer 사용을 불가능하게 만든다. 반면에 policy gradient에서의 multi-agent coordination은 높은 variance를 야기한다. 해당 논문은 CTDE framework를 채택하는 다음의 general-purpose multi-agent learning algorithm을 제안한다.
1. execution 시, local observation만 사용하는 학습된 policy로 이어진다.
2. env dynamics or agent communication에 대한 특정 구조의 differentiable model을 가정하지 않는다.
3. cooperative interaction뿐만 아니라 competitive or mixed interaction에 적용 가능하다.
- critic는 다른 agents의 추가 정보로 보강되는 반면 actor는 local 정보에만 접근할 수 있는 actor-critic policy gradient의 extension을 제안한다.
- centralized critic function은 명시적으로 다른 agents policies를 사용하므로, agent가 online으로 다른 agents의 대략적인 model을 학습하고 이를 자신의 policy 학습에서 효과적으로 사용할 수 있음을 보여준다. 또한 policy ensemble로 agent를 교육하여 multi-agent policy의 안정성을 향상시키는 method를 도입하므로 다양한 collaborator 및 competitor policies와의 강력한 interaction이 필요하다.
DDPG(Deep Deterministic Policy Gradient)
: DDPG는 구글 딥마인드에서 만든 모델로 DQN을 개선한 model-free RL 중 하나의 학습 방법으로 replay buffer를 추가한 off-policy algorithm이다. DDPG는 DQN을 continuous action space에 적용한 학습 방법으로 볼 수 있다.
- DPG(Deterministic Policy Gradient) + DQN(Deep Q-learning Network)를 합성한 형태로, DQN처럼 신경망과 replay buffer를 이용하고 DPG의 continuous action space에 대한 학습이 가능하다는 특징이 있다.

1) Action noise
: DDPG는 기본적으로 deterministic policy이므로 DQN과 같은 탐색(exploration)의 문제가 발생한다. DQN에서는 이러한 문제를 해결하고자 탐욕(e- greedy) 방법을 사용했지만, DDPG에서는 action에 random 값을 더하는 노이즈(noise)를 도입함으로써 간단히 해결했다.

Methods
Constraints
1. 학습된 policy는 execution 시, local observation만 사용 가능하다.
2. env의 differentiable model을 가정하지 않는다.
3. agent 간 communication method에 대한 특정 구조를 가정하지 않는다.
: 즉, differentiable communication channel을 가정하지 않는다.
Multi-agent actor critic
: Q-function는 일반적으로 훈련 및 테스트 시간에 다른 정보를 포함할 수 없기 때문에 Q-learning으로 이를 수행하는 것은 부자연스럽다. 따라서 critic이 다른 agents' policies에 대한 추가 정보로 보강되는 actor-critic policy gradient의 extension을 제안한다.
- CTDE method로 centralized training 시에는 Q-network를 이용해 action을 평가하지만, decentralized execution 시에는 각각의 agent가 독립적으로 policy network에 의해 행동한다.
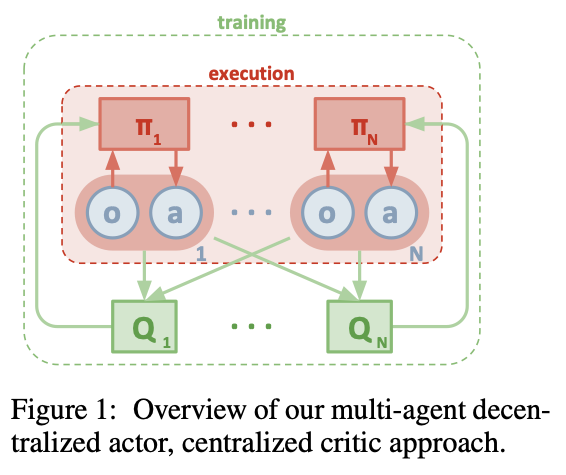
→ single-agent actor critic과 구조가 동일하지만 Q-network input으로, 다른 agents의 정보가 모두 들어간다는 것이 특징이며, N개의 agent가 있을 때, 각각의 agent는 자신만의 policy network와 critic network를 가지고 있다.
- 구체적으로, θ = {θ_1, ..., θ_N }으로 parameterized policy을 가진 N개의 agent가 있는 게임을 고려하고 π = {π_1,...,π_N}을 모든 agent policy 집합이라고 한다. 그 다음 agent i, J(θ_i) = E[R_i]에 대한 expected return의 gradient를 아래와 같이 쓸 수 있다.

→ actor network update는 policy network의 output인 확률과 Q-network의 output을 곱한 값에 대한 gradient ascent이다.
- 아래는 모든 agents' local observation x와 모든 agents' action a_1 , . . . , a_N을 입력으로 하는 action-value function이다. agent마다 각 Q^π_i는 개별적으로 학습되기 때문에 임의의 reward 구조를 가질 수 있다.


- deterinisitic policy인 경우. 기존 policy gradient method에서의 log probability는 state에서 특정 action으로 mapping해주는 parameterized actor function, 즉, N개의 continuous policy u_i로 대체되고 gradient는 아래와 같이 쓸 수 있다.

→ DPG는 state space에 대해서만 평균을 취하면 되기에, state와 action space 모두에 대해 평균을 취해야 하는 SPG에 비해 data efficiency가 좋다. 즉, 더 적은 양의 데이터로도 학습이 잘 이뤄진다.
- experience replay buffer D는 모든 agents' experience tuple(x, x′, a_1, . . . , a_N , r_1, . . . , r_N )를 포함한다. centralized action-value function은 다음과 같이 update된다. 여기서 μ′ = {μ_θ1′ , ..., μ_θN′}는 delayed parameter을 가진 target policies set이다.

→ critic network update는 Q-network의 Q-value와 실제 reward를 더해서 계산한 y에 대한 MSE loss이다.
- MADDPG의 기본 motivation은 모든 agents가 취한 action을 알면 policy가 변경되더라도 env가 stationary 하다는 것이다.
Additional training method
Inferring Policies of Other Agents
: 다른 agents' policies를 안다는 가정을 제거하기 위해, 각 agent i는 agent j의 true policy에 대한 approximation ^u_φji를 추가로 유지할 수 있다. 이 approximate policy는 entropy regularizer를 사용하여 agent j's action log probability를 최대화하여 학습된다. 여기서 H는 policy distribution의 entorpy이다.

- approximate policies로 equation 6의 y는 다음과 같이 계산된 approximate value ^y으로 대체될 수 있다. 아래 ^u'는 approximate policy에 대한 target network를 나타낸다. centralized Q-function을 update하기 전에, replay buffer에서 각 agent j의 최신 sample을 가져와 φ^j_i update를 위한 단일 grdient step을 수행한다.

→ online multi-agent 학습을 원할 경우, observation은 공유할 수 있지만, 다른 agents' action은 알 수가 없다. 이 경우, Q-network의 input으로 action을 넣을 수 없기 때문에, 다른 agents' action을 예측해서 online 훈련이 가능하다.
Agents with Policy Ensembles
: agents의 policy 변경으로 인한 env non-stationary 문제를 해결하기 위해, K개의 서로 다른 sub-policies u(k)를 학습을 적용할 수 있다. 각 episode에서 각 agent가 실행할 특정 policy u_i의 sub-policy를 무작위로 선택한다.
- 아래는 agent i의 maximaze하는 ensemble objective를 의미한다.

- 서로 다른 sub-policies가 서로 다른 episodes에서 실행되기 때문에 agent i의 각 sub-policy u(k)에 대해 experience buffer D(k)를 유지한다. 따라서 θ(k)에 대한 아래의 ensemble objective i의 gradient를 유도 가능하다.

→ MARL에서는 다른 agent의 policy 변화로 인한 env non-stationary 문제 해결을 위해, episode 마다 다른 policy를 배우게 한다. policy ensemble은 K개의 policy network를 이용해서 각각의 policy에 대해서 ensemble을 하는 방법이다.
MADDPG results
- 여러 env에서 실험해본 결과, MADDPG agents가 DDPG agent보다 성능이 더 높게 나오는 것을 확인할 수 있다.
- 왼쪽 그래프를 보면 DDPG를 cooperative agents로 사용할 때와 MADDPG를 cooperative agents로 사용할 때, adversary로 각각 MADDPG와 DDPG를 사용하여 비교하였을 때의 결과를 보여준다. 오른쪽 그래프는 cooperative agents 혹은 adversary에 각각 ensemble policy 적용 여부에 따른 결과를 나타낸다.

Conclusion
: 해당 논문은 agent가 모든 agents' observation과 action을 기반으로 centralized critic을 학습하는 multi-agent policy gradient algorithm을 제안한다. 이는 다양한 cooperative 혹은 competitive multi-agent environment에서 기존 RL algorithm보다 성능이 뛰어나다. 그러나 Q input space인 x가 agent 수 N에 따라 linear하게 증가한다는 문제가 존재한다. 이것은 주어진 agent의 특정 neighbor agent만 고려하는 modular Q-function으로 해결이 가능하다.
→ DDPG는 centralized Q-learning을 통해 다른 agents' policy를 예측함으로써, decentralized execution에 영향을 받아 action이 가능하다. 그러나 agent 수에 따른 state-space dimension 증가와 agent가 중간에 생성 및 유실되었을 때의 대처가 부족했다.
https://3neutronstar.tistory.com/6
[논문 리뷰](MADDPG)Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments(NIPS 2017),
이번에는 NIPS 2017 Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments을 리뷰하려고 합니다. 자세한 내용은 논문을 참조해주세요 Introduction & Background 강화학습, RL이 발전함에 따..
3neutronstar.tistory.com
https://jrc-park.tistory.com/194
MARL - MADDPG 이해하기
MADDPG(Multi-Agent Deep Deterministic Gradient) [paper] Model Architecture Policy $\pi_i$는 Policy Network로 상태에 대해서 행동을 결정하고 Critic Network $Q_i$는 Agent의 관찰과 행동에 대한 적정한..
jrc-park.tistory.com
https://ropiens.tistory.com/96
강화학습 논문 정리 2편 : DDPG 논문 리뷰 (Deep Deterministic Policy Gradient)
작성자 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB) 이번에는 Policy Gradient 기반 강화학습 알고리즘인 DDPG : Continuous Control With Deep Reinforcement Learning 논문 리뷰를 진행해보겠..
ropiens.tistory.com
[HUFS RL] 강화학습 : Reinforcement Learning: DDPG (Deep Deterministic Policy Gradient)
\-) 논문 살펴 보기 기존 Q-learning을 신경망을 이용해서 개선한 모델단점 : Discrete한 경우 밖에 적용이 되지 않음 => 보안한 방식이 DDPG(Deep Deterministic Policy Gradient\+) 네이쳐지 참고하기Actor와 Criti
velog.io
DQN에서 DDPG로
DQN 알고리즘에서는 상태변수가 연속공간 값이지만 행동은 이산공간 값으로 가정한다. 행동의 개수가 적으면 문제가 되지 않을 수도 있지만, 드론이나 로봇과 같은 실제 물리 시스템의 경우 행
pasus.tistory.com
댓글