Artificial Intelligence Review (2022) 55:895–943
Training scheme
: centralized training은 policy가 학습 도중 mutual 정보 교환을 통해 update가 되고, 이 추가 정보는 execution시 제거된다. 그에 반해, decentralized training은 각 agent가 자체적으로 update를 수행하고 외부 정보를 활용하지 않고 개별 policy를 처리한다. execution 단계에서 centralised method는 모든 agent에 대한 joint action을 계산하는 centralized unit에 의해 동작한다. 반대로 decentralized method에서는 decentralized execution에 대한 개별 policy에 따라 action을 결정한다.
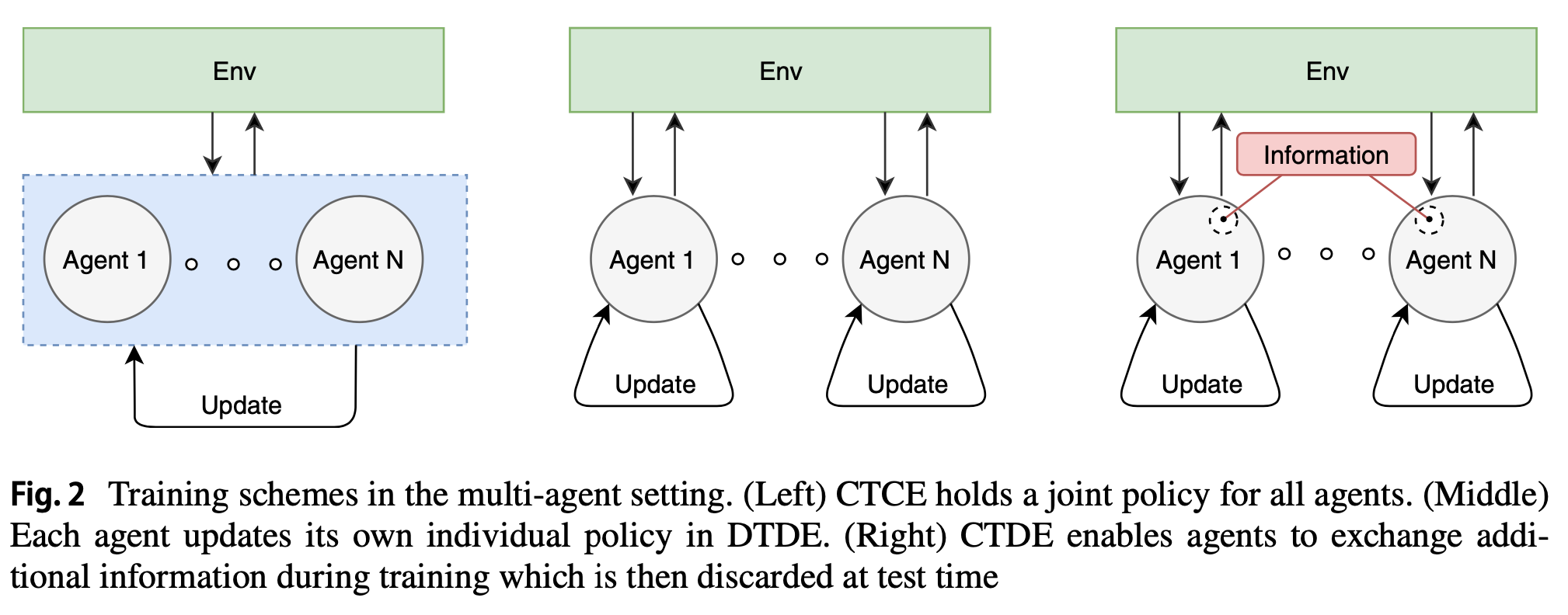
- 현재까지 training scheme에 따라 분류된 다양한 algorithm들이 존재한다. 이들 중 recent proposal을 살펴본다.
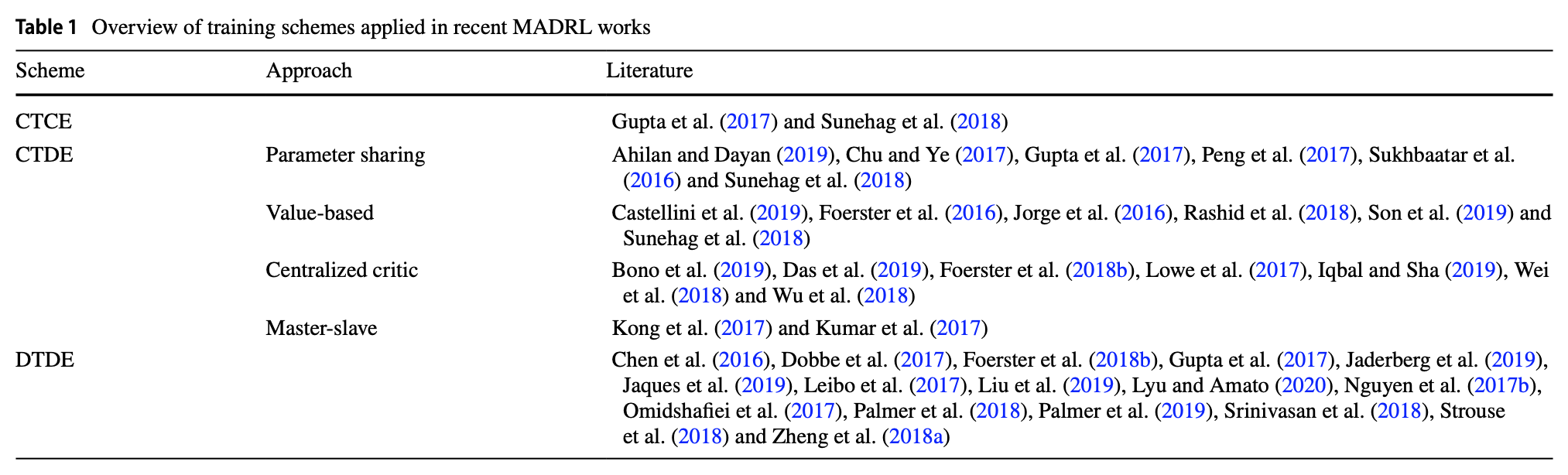
DTDE
CERT(Concurrent Experience Replay Trajectories)
: CERT라는 decentralized experience replay extension을 도입하여 독립적인 learner가 sample을 보다 안정적이고 효율적으로 렌더링하여, cooperative하고 partial observable한 setting에 도입이 가능하다.
Omidshafiei et al. (2017)
Extended the experience replay of Deep Q-Networks with leniency
: 저장된 state-action pair을 적용된 관대함의 양을 제어하는 decaying temparature value과 연결한다. 이것이 value-function update에서 낙관론을 유도하고 상대적인 over-generalization를 극복 가능하다.
Palmer et al. (2018)
Negative update intervals double-DQN
: 잘못된 coordination으로 이어지는 replay buffer에서 생성된 데이터를 식별하고 제거하는 mechanism이다.
Palmer et al. (2019)
Decentralized quantile estimators
: return 가능성을 기반으로 non-stationary transition sample을 식별한다.
Lyu and Amato 2020
Lenient reward approximation and a prioritized replay strategy
: 독립적인 learner의 향상을 목표로 하여 두 가지 보조 mechanism을 사용한다.
Zheng et al. (2018a)
Online evolutionary process
: 성능이 낮은 agent가 더 나은 agent의 mutated version으로 대체되는 distribution population-based training scheme를 사용한다.
(Jaderberg et al. 2019; Liu et al. 2019)
CTCE
Set of independent sub-policies
: centralized executor에서 모든 agents' joint action distribution을 independent action distribution로 분해했다.
Gupta et al. (2017)
CTDE
- at homogeneous agents env method
Parameter sharing
: sharing을 통해 학습 진행을 가속화하는데 도움이 되어, policy를 보다 효율적으로 습득이 가능하다.
Gupta et al. (2017)
Decompose value-function approximation
: joint value-function을 individual value-function의 combination으로 분해하는 것을 고려한다. 분해를 통해 각 agent는 단순화 된 sub-problem에 직면한다.
(Castellini et al. 2019; Rashid et al. 2018; Son et al. 2019; Sunehag et al. 2018)
- at heterogeneous agents method
One centralized critic
: 학습 중 추가 정보로 보강된 각 agent에 대해 하나의 critic만을 활용한다. critic에게는 모든 agent' policies에 대한 정보가 제공되는 반면, actor은 local observation만 인식한다. 결과적으로 agent는 명시적 communication에 의존하지 않고, non-stationary env를 극복할 수 있다.
Lowe et al. (2017)
Individual policies that share information with a centralized critic
: centralized critic과 정보를 공유하는 individual policy로 agent를 학습한다.
Bono et al. (2019)
Action-dependent baseline
: agent 수에 대해 더욱 악화되는 critic estimation의 variance를 기반으로 한다. critic estimation vrariance를 줄이기 위해 다른 agent의 정보를 포함하는 action baseline을 사용한다.
Wu et al. (2018)
Master-slave architecture
: decentralized slave와 정보를 공유하는 centralized master executor를 적용한다. 각 time-step에서 master는 slave로부터 local 정보를 받고 그 대가로 internal state를 공유한다. slave는 local observation과 master internal state에 따라 action을 계산한다.
Konget al. (2017)
Hierarchical methods
: hierarchical structure가 state goals 대신 reward에 의존하는 cooperative multi-agent setting에 agent의 2단계 abstraction을 적용했다. 이러한 approach가 decentralized control problem에 적합할 수 있음을 보여주었다.
Ahilan and Dayan (2019)
Trends
: 최신 MADRL에서는 현재의 문제들을 해결하기 위해 자주 적용되는 경향을 확인할 수 있다.
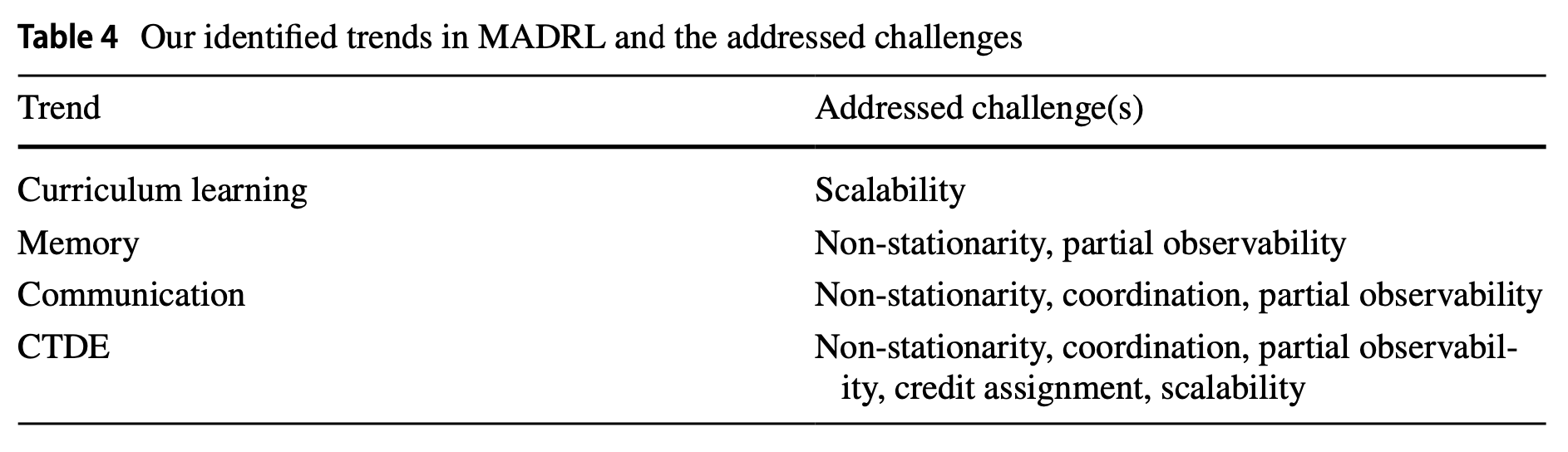
Scalability
: scalability를 다루기 위해 learning process를 단계로 나누는 approach로 curriculum learning를 사용한다.
- 소량으로 시작하여 학습 과정에 걸처 agent 수를 점차 늘려 대규모 학습이 가능하게 한다.
(Gupta et al. 2017; Long et al. 2020; Narvekar et al. 2016)
- 또는 curriculum을 사용하여 agent가 처음에는 비교적 쉬운 task에서 학습하고, 예측이 향상됨에 따라 점차 더 복잡한 task에 직면하는 난이도 단계를 생성할 수도 있다.
(Vinyals et al. 2019)
- 그 외에도 curriculum training은 agent action의 출현을 조사하는데 사용된다. curricula는 env dynamics에서 공학적 변화를 설명한다. agent는 다른 agent의 전략적 변화 및 시간이 지남에 따라 자신의 action을 조정하므로 agent 간 경쟁이 발생할 수 있다. 이러한 continual adaption을 auto curricula라고 한다.
(Leibo et al. 2019; Baker et al. 2020; Sukhbaatar et al. 2017; Svetlik et al. 2017)
Memory
: experience를 암기하기 위해 recurrent units가 내장된 neural network를 사용한다.
- state transition history와 다른 agent action을 추적하는 기능을 가짐으로써, multi-agent 및 partial observable state로 인한 env non-stationary 문제를 축소할 수 있다. 또한 복잡한 task에서도 잘 관리가 가능하다.
(Omid- shafiei et al. 2017; Baker et al. 2020; Berner et al. 2019; Jaderberg et al. 2019)
Communication
: communication skill을 개발하여 사용한다.
- interactive agents 간의 language 출현을 조사하기 위해 새로운 computational approach를 사용할 수 있다.
(Lazaridou and Baroni 2020)
- agent는 intention을 표현함으로써 coordination을 조정하고 consensus를 찾을 수 있다.
(Foerster et al. 2016)
- agent가 history를 공개할 때, single learner의 관점에서 non-stationary를 피할 수 있다.
- 또한 agent는 partial observability를 완화하기 위해, 다른 agent와 local observation을 공유할 수 있다.
(Foerster et al. 2018b; Omidshafiei et al. 2017)
CTDE paradigm
: 학습 중 information sharing을 가능하게 하는 paradigm이 유망하다.
- observation-action history, function values, or policies와 같은 local 정보는 훈련 중에 모든 agent가 사용할 수 있게 하여, 개별 agent 관점에서 env를 stationary하게 만들고 partial observability를 감소시킨다.
(Lowe et al. 2017)
- 또한 credit assignment problem은 모든 agnet에 대한 정보를 사용할 수 있을 때, 해결할 수 있으며 centralized mechanism은 individual contribution을 해당 agent에 귀속시킬 수 있다.
(Foerster et al. 2018b)
- 추가로 individual agent의 정보 부족을 보완하고 학습 process를 가속화 할 수 있는 조정 및 확장이 연구중이다.
(Gupta et al. 2017)
Future work
multi-goal learning
: 각 agent가 최적화해야하는 개별적으로 연결된 목표가 있는 학습이다. 그러나 agent가 다른 agents도 자신의 task에서 성공하도록 허용하는 경우에만 global optimality를 달성 가능하다.
(Yang et al. 2020)
multi-task learning
: multi-goal learning과 유사하게 agent가 하나의 task뿐만 아니라 관련된 다른 tasks에서도 잘 수행할 것으로 예상되는 학습이다.
(Omid- shafiei et al. 2017; Taylor and Stone 2009)
Safe MADRL
: 자율 action을 수행하는 agent는 안전 보장을 유지하며 시스템 성능을 보여야 하기 때문에 safety는 중요한 속성이다. single agent RL의 여러 task는 safety와 연결되어 있지만, multi-agent에 대한 적용 가능성은 아직 초기 단계에 있다.
(Zhang and Bastani 2019; Zhu et al. 2020)
Communication learning
: agent 간 interaction 학습에 대한 관심 또한 높아지고 있다.
(Shalev-Shwartz et al. 2016)
Evolutionary methodologies
: 진화적 방법론 사이와 MADRL 사이의 교차점을 제공한다. evolutionary algorithm은 multi-agnet RL의 다음과 같은 다양한 context에서 사용되었다.
intrinsic motivation (Wang et al. 2019), shaping rewards (Jaderberg et al. 2019), generating curricula (Long et al.2020) and analyzing dynamics (Bloembergen et al. 2015)
Challenging problem
Heterogeneity
: 대부분의 연구는 agent가 공통 관심사를 공유하고 common interest를 최적화하는데 중점을 두고, 이러한 목표는 CTDE paradigm에서 일반적으로 유익하다. 그러나 이질성은 agent가 자신의 interest, goal, experience, knowledge, different skills, capabilities를 가질 수 있음을 의미한다. 실제 상황에서 agent는 결정을 내려야 하는 region 및 이기종 정보에만 접근이 가능하다.
Curse of dimensionality
: state-action space와 combinatorial possibilities of agent interaction는 agent 수에 따라 기하급수적으로 증가하므로 충분한 탐색 자체가 어려운 문제가 된다. agent가 partial observable하거나 continuous env의 경우에는 더욱 심각해진다. neural network와 같은 강력한 function approximator는 continuous space아 large scope에 잘 대처할 수 있지만, 크고 복잡한 space를 충분히 잘 explore하는 바업ㅂ과 대규모 combinatorial optimization problem에 대한 미해결 질문이 남아있다.
(Busoniu et al. 2008; Hernandez-Leal et al. 2019)
댓글