University of Oxford, United Kingdom Canadian Institute, Google DeepMind, May 2016
Abstract
: MDRL에서는 효용을 극대화하기 위해, env를 감지하고 행동하는 multiple agents의 문제를 고려해야만 하므로 정보 공유를 위한 communication protocol이 필요하다. 복잡한 multi-agent env에서의 patial observability를 DNN을 수용하여 end-to-end agent 간의 학습을 해결한다. 해당 논문에서는 DQN 학습을 사용하는 RIAL(Reinforced Inter-Agent Learning)과 학습 도중 별도의 communication channel을 통해 backpropagation을 사용하는 DIAL(Differentiable Inter-Agent Learning)을 제안한다.
Introduction
: partially observable, sequential multi-agent decision making하는 fully cooperative problem에 대한 algorithm을 제시한다. 모든 agent는 Markov state를 관찰 불가능하고, 각 agent는 해당 state에 관련된 private obeservation만을 받는다.
env에 영향을 미치는 action을 취하는 것 외에도, 각 agent는 별도의 channel capacity를 통해 다른 agent와 communicate 가능하다. partial observability와 limited channel capacity로 인해 agent는 자신의 action을 조정하고 작업을 해결 가능한 communication protocol을 찾아야 한다.
Setting
: RL problem을 multi-agent와 parital observability 고려하는 관점에서, agent는 communication에 대한 동기부여를 가질 수 있다. 사전에 communication protocol이 제공되지 않으므로 agent에게는 이러한 protocol이 필요하다.

: 모든 agent가 최대화 하려는 동일한 discounted sum of rewards

: 모든 agent가 관찰 불가능한 기본 Markov state

: 각 agent가 받는 private observation, S_t와 관련됨

: 각 time-step에서 agent가 env에 영향을 미치는 env action

: 각 time-step에서 다른 agent로부터 관찰되는, env나 reward에 영향을 주지 않는 communication action
CTDE(Centralized Training Decentralized Execution)
: centralized planning과 decentralized execution은 multi-agent planning의 표준 패러다임이다. 즉 agent 간의 communication은 centralized algorithm으로 수행되는 learning동안 제한되지 않는다. 그러나 learned policy를 execute하는 동안 agent는 limited-bandwidth channel을 통해서만 소통할 수 있다.
Methods
RIAL(Reinforced Inter-Agent Learning)
1. partial observability를 해결하기 위해, recurrent network과 함께 deep Q-learning을 사용한다.
: action과 communication selection을 위해 DRQN을 independent Q-learning과 결합한다.
- 각 agent의 Q-network는 다음을 나타내며, 각 agent의 hidden state와 observation에 조건한다.

→ agent가 partially observable하게 얻는 state, 다른 agent의 action, agent의 hidden state, agent가 취하는 env로의 action의 parameters로 Q-network가 표현된다.
2. agent는 자신만의 network parameter를 학습하여 다른 agent를 env의 일부로만 취급하고 action한다.
: |U||M| action space의 output network가 필요하지 않도록, network를 각각 env, communication action에 대한 Q^a_u와 Q^a_m으로 분할한다. 이는 결국 |U|+|M|의 action space로 감소시키는 효과를 얻는다. action selector는 e-greedy policy를 이용하여 Q_u와 Q_m에서 u^a_t와 m^a_t를 별도로 선택한다. 따라서 network에는 |U| 와 |M| 각각의 출력을 최대화 하는 방향으로 action select가 진행되어야 한다.
- Q_u와 Q_m은 모두 DQN을 사용하여 훈련되고 이러한 network의 분할은 다음의 특성을 가진다.
1) multi-agent가 동시에 learning할 때 발생하는 non-stationary를 고려하여 오류로 취급되는 experience replay를 제거할 수 있다.
: 여러 agents들이 동시에 학습할 경우, 다른 agent에게 env가 non-stationary하게 바뀌는 것처럼 다가오기 때문에, experience replay를 제거한다.
2) partial observability를 고려하여, 이전 agent가 취한 action u와 m을 다음 time-step의 input으로 제공한다.
: agent가 선택한 action u,m를 서로에게 input으로 제공한다.
→ 결국 각 agent는 다른 agent의 action을 고려하는 network와 env와의 action을 고려하는 network를 각각 최대화하는 방향으로 action을 선택한다. 이때 action selector는 e-greedy하게 각 network에서의 action을 선택한다.
3. agent는 decentralized learning과 동시에, decentralized execution로 취급된다.
: agent를 독립적인 network로 취급하므로, problem setting이 centralized 할지라도 learning 단계는 decentralized하다.
→ RIAL은 decentralized learning으로 진행되다싶이 하였으며, communication protocols를 학습하는데 중요한 feedback mechanism이 없다.
4. 모든 agent 간에 공유되는 parameter의 single-network를 훈련시키는 확장 방법이 존재한다.
: execution은 decentralized하게 유지되며 이 시점에서 다른 action으로 이어지는 다른 observation을 받는다.
1) Parameter sharing
: decentralized learning을 agent 간 parameter를 공유하여 centralized learning을 활용하도록 RIAL를 확장할 수 있다. 이 변형은 모든 agent가 사용하는 하나의 network만 학습한다. 그러나 agent는 서로 다른 observation을 받고, 다른 hidden state를 진화시키기 때문에 여전히 다르게 행동한다.
- 또한 각 agent는 자신의 index a를 입력으로 받아 특화될 수 있다. DQN의 풍부한 표현은 common policy 학습을 촉진하는 동시에 specialization이 가능하다. 학습해야하는 parameter 수를 크게 줄여 학습 속도 또한 높일 수 있다.
- parameter sharing에서 agent는 이전 action inputs인 u^a_t-1, m^a_t-1와 agent index a를 포함한 다음의 2가지 Q-function을 학습한다.



- decentralized execution 중에는, 각 agent는 learned network의 자체 copy를 사용하여 own hidden state를 발전시키고, own action을 선택하며, communication channel를 통해서만 다른 agent와 통신한다.
→ basic RIAL은 별도의 channel로, env action과 other agents action의 Q-function을 각각 최대화하는 두 개의 network를 통해 정보를 교류하며 학습한다. extension RIAL의 경우에는 모든 agents' network들을 하나로 통합한 parameter shared network만 학습하여 속도 개선 및 common policy 습득이 가능하다.
RIAL flow
: 모든 Q-value는 env, communication actions를 모두 선택하는 action selector에게 제공된다. 빨간색으로 표시된 선인 gradient는 선택한 action에 대해 DQN을 사용하여 계산되고, single-agent의 Q-network를 통해서만 흐른다.

DIAL(Differentiable Inter-Agent Learning)
: centralized learning이 parameter sharing보다 학습을 개선할 수 있다는 insight를 기반으로 한다. 특히, RIAL은 agent 내에서 end-to-end 학습이 가능하지만, agent 간 end-to-end 학습은 불가능하다. 즉, agent간에 gradient가 전달되지 않는다.
- centralized learning 중에 agent 간 real-valued message를 전달할 수 있도록 하여, communication action을 agent 간 bottleneck connection으로 처리한다. 결과적으로 gradient가 통신 채널을 통해 전달되어, agent 간에도 end-to-end 교육이 가능한 시스템이 생성된다. decentralized execution 중에 real-value 메시지는 discrete되어, task에서 허용하는 communication action set에 매핑된다. DIAL은 agent 간에 gradient를 전달하기 때문에 본질적으로 딥러닝 방법이다.
→ DIAL은 centralized learning과 Q-network의 조합을 통해, 매개변수 공유 뿐만 아니라 communication channel을 통한 gradient push가 가능하다. 따라서 DIAL은 agent 간 end-to-end 학습이 가능하다. agent 간 gradient 이동은 풍부한 feedback을 제공하여 error를 통해 optimize하여 최적의 protocol를 찾을 수 있다.
1. centralized learning 동안, communication actions은 agent 끼리의 출력과 입력의 연결로 새롭게 대체된다.
: 즉, task가 discrete messages로 communication을 제한하는 동안, agent는 학습할 때 서로에게 real-valued message를 자유롭게 보낼 수 있다.
→ 이러한 message는 network activation과 같은 기능을 하고, channel을 따라 gradient를 전송 가능하므로 agent간 end-to-end backpropagation이 가능하다.
2. C-Net network와 gradient를 전달하는 DRU unit이 존재한다.
: C-Net이라 부르는 network는 다음 2가지 distinct types of values를 출력한다.


: action selector에게 주어지는 env actions에 대한 Q-values

: action selector를 통과하지 않고, discretise/regularise unit DRU(m^a_t)에 의해 처리되는 다른 agent에 대한 real-valued message
- DRU unit은 message m^a_t에 대해 centralized learning 중에 regularise와 discrete를 적용한다.
1) centralized learning 중, logistic function을 통해 regularise한다. 이 때, σ는 channel noise의 standard deviation이다.

2) decentralized execution 중, Gausian noise를 통해 discreties한다.
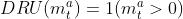
- RIAL의 Q_u와 DIAL의 Q에 대한 gradient chain은 DQN loss를 기반으로 한다. learning 시에, DIAL에서 agent 간의 gradient를 이용하면, RIAL에서 Q_m에 대한 DQN loss보다 더 풍부한 backpropagated error를 제공한다. 만약 DQN loss가 0이 아니라면, incoming gradient는 더 많은 정보를 포함한다.
→ RIAL보다 DIAL의 방식에서의 gradient가 더 많은 정보를 포함하므로 network에서 DQN loss를 최소화하기 위해 message를 조정하는데 필요한 error & trial이 줄어들고, 좀 더 빠르게 수렴할 수 있다. 결과적으로, DIAL이 RIAL보다 성능이 뛰어나다.
DIAL flow
: message m^a_t는 action selector 대신 DRU에 의해 처리되고 다음 C-network에 continuous value로 전달된다. 따라서 gradient는 받는 사람에서 보낸 사람까지 agent를 가로질러 흐르게 된다.

DIAL algorithm

1. 각 agent a는 초기화 진행 후, 이전 time-step의 m^a_t-1 message를 받고 C-net에서 evaluate한다.

- 각 agent a 마다 반복
- 이전 time-step의 m^a_t-1 message를 얻음
- C-Net에서 Q-value, m^a_t 출력
- epsilon greedy하게 max Q-value의 u^a_t를 선택
- m^a_t를 DRU unit에 동과
- env로부터 reward와 next state를 얻음
2. episode가 끝난 뒤, gradient push가 이루어진다.

- 각 agent a 마다 반복
- max Q-value를 이용하여 y^a_t 계산
- y^a_t와 현재 action의 Q-value 차이에 대해 gradient 계산
- communication gradient chain update:
- first term: message m^a_t의 next step에 대한 total estimation error를 계산
- second term: received message m^a'_t+1에 대한 m^a_t의 편미분을 message gradient u^a'+t+1에 곱해 m^a_t의 future reward impact를 계산
- 계산한 값들을 통한 gradient update
Experiments
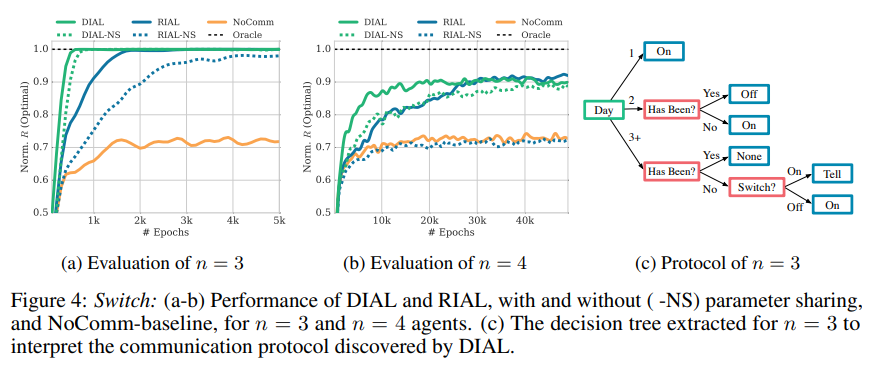
- Switch riddle에서 DIAL는 RIAL보다 빠르게 optimal에 수렴하며, parameter sharing은 두 방법 모두에서 속도를 높인다.
- MNIST games에서 DIAL이 다른 method보다 성능이 우수함을 볼 수 있다.

Conclusion
: 해당 논문은 deep network, differentiable communication, neural network architecture design, channel noise, tied parameters 등의 요소들을 고려하여 communication protocol을 학습할 수 있었다. 이는 communication을 어떻게 학습할 지에 대해 deep learning적인 접근의 시초로 볼 수 있다.
6. Learning to Communicate with Deep Multi-Agent ReinforcementLearning - Deep Multi-Agent Reinforcement Learning
6. Learning to Communicate with Deep Multi-Agent ReinforcementLearning
kilmya1.gitbook.io
댓글