IEEE TRANSACTIONS ON SMART GRID, VOL. 11, NO. 3, MAY 2020
Abstract
: EV charging 수요가 급증하는 피크 시간에 배전망의 변압기에 과부하가 걸리는 문제를 해결하고자 부하를 줄이고 가능한 공평하게 EV를 충전하기 위해 여러 방법이 제안되었지만, 일반적으로 single type 요금제 또는 배전망에 대한 강력한 가정을 두는 전제를 사용하였다. 해당 논문에서는 EV recharging 도중, 동시에 변압기 과부화를 피하고 에너지 비용을 최소화하는 MultiAgent Selfish COllaborative architecture(MASCO)을 제안한다.
Nomenclature


Introduction
1. MASCO는 distributed Multiagent Multi-objective RL에 기반하며, EV가 배터리를 충전하거나 적절한 시간 동안 대기할 수 있는 시기를 locally 정의한다.
- EV는 locally observable 정보와 communication만을 통해 동작하는 agent라고 볼 수 있다.
- local 정보는 EV's own battery level과 각 env 정보인 변압기 부하와 에너지 비용으로 구성된다.
- EV는 communication을 통해 다른 EV로부터 정보를 얻는다.
2. MASCO는 coordinated charging problem을 해결하기 위한 approximated algorithm으로 제공한다.
- MASCO agents는 heuristic에 의해, selfishly 혹은 collaboratively하게 행동할지 결정한다.
- MASCO agents는 모든 유형의 policy or learning algorithm에 따라 동시에 작동할 수 있으며 별도의 수동 입력이 필요하지 않다.
→ MASCO는 사용 시간 및 동적 가격 환경 모두에서 coordinate charging을 배운다는 것을 실험에 의거하여 알 수 있다.
Problem statement
: 지역 배전망이 다수의 주거 가구에 연결 되어 있는 주거 지역의 전형적인 상황을 가정한다. 각 가정에는 소비자가 개인 교통 수단으로 사용하는 EV가 존재한다. 만약 너무 많은 EV가 한번에 충전을 시도하면, 변압기 과부화가 발생하므로 각 EV는 다른 차들과의 communication link를 통해 협업하여 이를 방지한다. 제안한 아키텍처는 지역마다 다를 수 있는 배전망의 실제 구현에 영향을 받지 않는다. 이 때, 에너지 가격은 유동적일 수도 고정적일 수도 있다.
1. Requirement ①: Distributed Solution
: 모든 agents는 local 정보와 communication으로 부터 받은 정보에 근거하여 그들의 policy를 정의한다.
2. Requirement ②: Self-Interested Agents
: 멍청한 model이 존재하거나 일부 agent가 협력을 거부할 수 있기 때문에 agent가 반드시 동질적이거나 완전히 협력적일 필요는 없다고 가정한다.
3. Requirement ③: Unpredictable Consumer Behavior
: 사용자 EV 사용 프로필은 일반적으로 대략적으로 근사할 수 있는 분포를 따른다. 그러나 소비되는 시간과 에너지는 정확히 예측이 불가능하다.
→ 해당 문제 정의에서 MASCO가 optimal policy를 찾는 것을 증명할 수는 없지만, 실제 시나리오에서 잘 동작함을 확인할 수 있다.
Proposal
: MASCO는 agent가 변압기 부하와 에너지 가격만 관찰할 수 있으면 되므로 배전 인프라에 대해 minimal assumption을 하기 때문에 다른 접근 방식과는 다르다. 또한 heterogeneous agents에 대처할 수 있으며 모든 type of tariff를 처리할 수 있다. 이 system은 다음 세 가지 경쟁적 objectives를 동시에 optimize함을 목표로 한다.
Objectives to optimize
1. Battrey Level
: 소비자는 매일 이동 전 높은 배터리 잔량을 필요로 함으로 이를 최대화하는 것을 목표로 한다.
2. Price Paid
: agent는 소비자의 총 에너지 비용을 최소화 하는 것을 목표로 한다.
3. Transformer Overload
: agent는 명시적으로 변압기 과부화 수를 최소화 하는 것을 목표로 한다.
- multi-objective problem은 objectives 간에 서로 trade-off가 있는 set of policies이며, 이 trade-off는 소비자의 preference를 따르고, 그에 따른 utility function f가 존재한다. solution set에는 최소 한 개의 optimal policy가 존재하며 이는 coverage set라고도 불린다.
RL Procedure
- 각 agent는 협력할 수 있는 주위 agents과 communication link를 가지고 있다. 이 때, 다른 agents의 모든 action은 관찰되지 않으며 환경의 stochastic affects로 간주된다.
1. Selfish optimization
: agent는 먼저 multi-objective를 optimize하는 selfith policy π_s를 출력한다.
2. Collaborative optimization
: local agent는 또한 자기가 선택한 action이 다른 agents에게 영향을 주는지 학습하는 collaborative policy π_c를 학습한다.
3. Cooperation Criterion
: agent가 π_s 혹은 π_c 중 어떤 것을 실행할 지 선택한다.
Foundations
Utility function f
: 사용자의 utility를 나타내는 value-vector function이며, utilitiy function이 학습과 실행 전반에 걸쳐 고정되고 선험적으로 알려지면 여러 rewards들을 single one으로 축소 가능하다. 이는 f가 아래의 식에 따라 linear하고, w가 objective의 relative importance를 encoding하는 weight vector이어야만 한다.
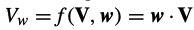
- 그러나 weights가 알려지지 않았거나 바뀔 것이라고 예측되는 상황으로 예를 들어 소비자 preference가 시간이 지남에 따라 변할 수 있듯이, 다양한 objectives를 명시적으로 고려하고 소비자의 preference가 변할 때마다 그에 따라 policy를 조정해야 한다.
MOPOSG(Multi-Objective Partially Observable Stochastic Game)
: 또한 MORL, SG(Stocharsic Games)의 MARL를 융합하여 coordinated charging problem을 다음과 같은 구성 요소들을 포함한 MOPOSG로 모델링한다.
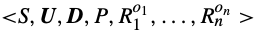

- 학습 문제에서, P와 R은 observation과 reward returns만 관찰 가능한 agent에게 알려지지 않는다.
DWL(Distributed W-Learning)
: MASCO와 비슷한 algorithm으로는 각 agent가 협력 가능한 일련의 neighbors를 가지고 있던 DWL이 있다. 이는 single reward function이 필요하지 않으며, heterogeneous agents가 있는 domain에 적용이 가능하다. 그러나 사용자 preference에 따라 선호하는 objective의 policy를 제공할 수 없다.
- W-learning이란 agent가 각 policy에 따른 action-value pair에 대한 Q-value를 학습하는 Q-learning과는 다르게, agent가 각 state에서 해당 policy에서 출력한 action을 하지 않을 경우 받은 reward와 관련하여 어떤 일이 발생하는지 학습한다. 이는 W-value or W(s)로 표현된다.
→ 따라 해당 논문에서는 coordinated charging problem을 customized, distributed, scalable way로 해결하기 위해 DWL과 유사한 architecture로 MASCO를 제안한다.
MASCO: Solving the coordinated charging problem with RL
- MOPOSG로 모델링되기 때문에 MASCO는 selfish agent에 의해 도입된 partial observability와 stochasticity를 고려한다. 또한 예측할 수 없는 소비자 행동은 env를 stochasticity하게 만든다.

1. MASCO는 multiple policies를 아래와 같이 distributed manner로 학습한다.
- each agent는 objective와 local observation function 당 한 개의 reward function을 가진다.
1) Selfish optimization
: agent는 selfish manner로 각 reward function r^i마다의 selfish policy π^i_s를 학습한다.
- 아래는 모든 local objectives에 대한 reward vector이며, o는 reward function의 개수를 의미한다.

- 아래는 각 local rewards에 연관된 set of Q-tables이며, Q^i는 objective i에 관련된 Q-table이다.

- 아래는 state s_k에 대해 action a^s를 반환하는 selfish optimization function이다. SO는 time-step에서 주어진 objectives들 중 relative importance에 따라 policy를 번갈아 가며 대략적인 non-stationary policy를 도출한다.
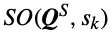
2) Collaborative optimization
: agent i가 협업하고 싶은 각 neighbor agent j에 대해, collaborate manner로 각 reward function r^i,j마다의 collaborate policy π^i,j_c를 학습한다.
- 아래는 other agent objectives에 연관된 set of Q-table이며, Q^j,i는 agent j의 objective i, G는 neighbor agents, o_j는 reward function의 개수를 의미한다.
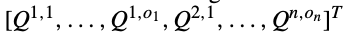
- 아래는 state s_k에 대해 action a^c를 반환하는 collaborative optimization function이다. CO는 time-step에서 가장 도움이 필요한 agent를 정의하고 하나의 objective를 optimize하기 위해 협력한다.

3) Cooperation Criterion
: k time-step에서 agent가 selfish or cooperative하게 행동해야 하는지 선택한다.
→ SO는 local agent에게, CO는 협력적인 agent에게 최상의 action을 제공하며 CC는 양측의 균형을 유지한다.
2. CO 및 SO는 Linear Scalarization으로 구현된다.
: linear scalarzation은 utility를 모델링하는 일반적인 function이다. non-linear scalarization 또한 사용할 수는 있지만 수렴이 불가능 할 수 있으므로 신중하게 선택해야 한다.

- f는 scalarization function이며 아래와 같이 정의된다. w는 vector of 사용자 preference이며, agent마다 다를 수 있다. 이 때, j는 selfich case일 자신의 agent에 해당한다.
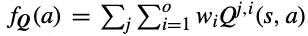
→ SO와 CO는 사용자 preference weight과 곱해지는 모든 objectives 마다의 Q-table의 summation의 최댓값을 사용한다.
3. CC를 정의하기 위해서는 W-function이 필요하다.
: CC를 정의하기 위해서는 W-function을 계산한다. W-table은 policy를 준수하지 않을 경우 long-term reward를 더 많이 잃을 것으로 예상되는 objective를 나타낸다.
- W-value는 아래 equation에 따라 주어진 objective에 대한 best action이 실행되지 않은 경우에만 update된다. r^i_k는 objective i에서 관찰된 reward, Q^i는 objective i에 연관된 Q-table이다.

- winning action a^s or a^c는 아래와 같이 정의된다. C는 collaboration에 가중치를 부여하고, W_s는 가장 높은 Q-value를 갖는 objective와 관련된 W-value, W_c는 Q^c와 관련된 W-value를 의미한다.
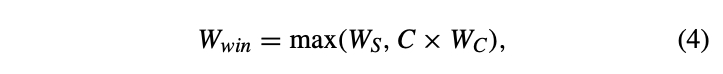
- 만약 W_win = W_s이면, a_k = a^s_k이고, 아니라면 a_k = a^c_k이다.
- 모든 objectives에 대한 selfith와 collaborative W-value는 W_win과 관련된 것을 제외하고 Eq(3)에 의해 update된다.
→ CC는 MASCO가 local 관찰 및 communication에만 기반하여 두 policy 중에서 선택하는 방법을 단순화하여 대략적인 솔루션을 제공하는 heuristic이다.
MASCO algorithm

1. agent는 각 local objective (Q^i, W^i)을 위한 하나의 (Q-table, W-vector) pair와 G에 속한 agent의 각 objective를 위한 (Q^ag,i, W^ag,i) pair를 임시로 초기화한다. (step 1-4)
2. agent는 자신의 current state를 관찰하고 다른 agent와 communicate하여 their state를 수신한다. (step 5)
3. a^s_k와 a^c_k가 wiehgted Q-value를 maximizing하며 선택된다. (step 7-8)
- reward function의 척도가 다를 수 있으므로 resulting policy에 문제가 발생함을 방지하고자 action selection 전에 normalization을 진행한다.
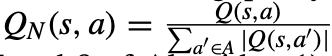
4. action a_k는 W_win에 따라 선택되고 e-greedy strategy를 따른다. (step 9-10)
5. 모든 actions 실행 뒤에, 모든 Q-tables는 observed local rewards와 communication으로 받은 rewards에 따라 update된다.
W-vectors는 W_win을 제외하고 모두 update된다. (step 12-28)
6. agent는 next state를 관찰하고 같은 진행을 반복한다.
MASCO assumtion
1. Communication
: agent는 local state 및 reward가 필요하므로, 모든 decision steps에서 모든 neighbor agents A_g ∈ G와 communicate 할 수 있어야 한다.
2. Knowledge of other friendly agents
: local agent는, G에 속한 모든 agent가 올바른 수의 Q-table를 초기화 하기 위한 reward functions의 수를 알아야 한다.
- agent가 local action의 function으로 모든 Q-table을 생성하기 때문에 neighbor agent는 다른 action sets와 state space를 가질 수 있다.
3. Friendly agents discovery
: agent는 set of neighbor agent G를 인식할 수 있어야 한다.
Coordinated Charging RL Modeling
: local state는 모든 time-step에서 agent가 사용할 수 있는 다음 정보에 따라 설정된다.
1. Current battery level
: 소비자의 충전 상태로 20% 단위로 discretize되며 charge action 혹은 daily journey에 의해 영향을 받을 수 있다.
B = {0 − 20%,20 − 40%,...,80 − 100%}
2. Current time
: 오늘의 현재 시간으로 15분 단위의 슬롯으로 제공된다.
= {0:0, 0:15, . . . , 23:45}
3. Transformer load
: 마지막 time-step에서의 load로, 변압기와의 communication을 통해 kW단위로 수신되며 다음과 같이 discretize된다.
ζ = {LOW, MEDIUM, HIGH, OVER}
1) LOW: 최대 원하는 부하의 최대 60%
2) MEDIUM: 원하는 최대 부하의 60%-80% 사이
3) HIGH: 원하는 최대 부하의 80%-100% 사이
4) OVER: 위 interval보다 큰 부하
4. Location
: EV는 집에 있을 수도, 여행할 수도 있다.
L = {at home, traveling}
→ 이러한 state variables에 따라 완전한 local state space는 S_j = B × × ζ × L로 정의된다.
→ local action apce는 A_j = {charge, not charge}로 구성된다.
Reward function
: transition function P(s_k, d_k, u_k+1, s_k+1)는 환경이 반응하는 방식을 모델링한다. agent는 P를 모르고, 알려지지 않은 환경에서 작동하는 방법을 reward function을 통해 배워야 한다. 해당 논문에서 objective는 다음 reward function로 encoding된다.
1. Battery level
: 배터리를 높은 수준으로 유지하는 사용자 만족도이다. agent가 사용할 수 있는 배터리 충전량의 20%마다 +10이 된다.
2. Price paid
: 에너지 비용을 최소화 하는 것이다. p를 k에서 kWh당 에너지 가격, c를 k에서 agent가 소비한 에너지라고 할 때, 1 / p x c로 정의된다. 즉, 비용이 작을수록 보상이 커진다. c가 0인 경우, EV의 일반적인 에너지 소비와 p가 소비자 또는 설계자가 정의한 평균 가격과 동일한 c에 해당하는 값을 반환한다.
3. Transformer overload
: 변압기 과부하를 방지한다. 변압기가 과부하 상태이고 agent가 충전중이면 0을 받는다. 변압기 부하가 원하는 범위 내에 있거나 agent가 충전되지 않는 경우 +50을 받는다.
MASCO results
댓글