IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 23, NO. 7, JULY 2022
Abstract
: UAV(unmanned aerial vehicle) 함대를 관리하는데 collision-free path planning은 중요한 challenge이다. 해당 논문에서는 UAV routing policy 설계를 고려하고, 3M-RL이라는 multi-solution, multi-agent, mean-field 학습 algorithm을 제안한다. 각 UAV는 local obseration을 기반으로 결정을 내리고 다른 UAV와 통신하지 않는 decentralized execution으로 동작한다.
Introduction
: UAS(unmanned aircraft system)에서 path planning, 구체적으로 각 UAV가 목적지에 안전하게 도달하기 위한 policy에 중점을 둔다. 해당 논문에서 path planning은 fixed path를 식별하는 것이 아니라 policy에 따라 주변 env에 따라 실시간으로 동적이고 적응적으로 path를 조정하는 과정을 의미한다. 이를 2D horizontal space와 3D space에서 collision avoidance problem을 고려한다.
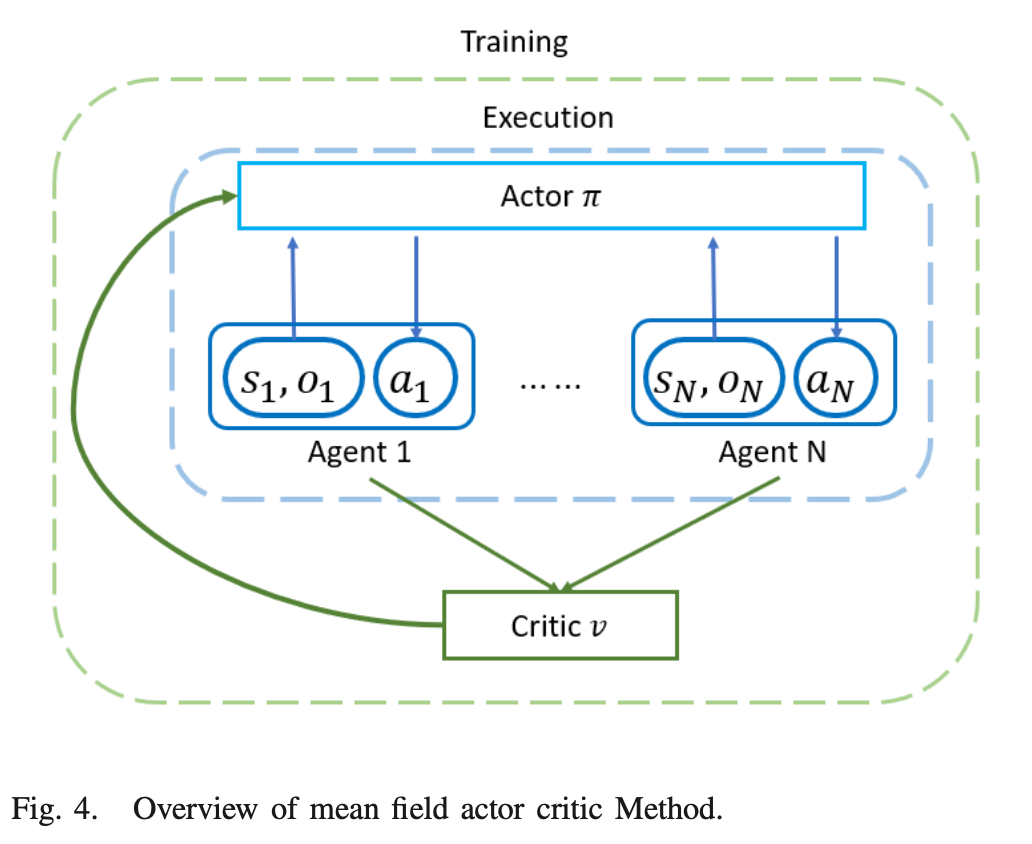
- 우리는 모든 UAV가 동일한 entitiy에 속하는 시스템을 고려하여 동일한 policy를 구현한다. 이 policy는 CTDE method로 실행된다.
- state space 또는 policy complexity는 UAV 수가 증가함에 따라 exponentially하게 증가한다. 따라 curse of dimensionality를 위해 mean-field approach를 도입한다.
Main concept
: UAV가 서로 안전한 거리를 유지하면서 목적지에 도달해야하는 routing problem을 고려한다. UAV agent는 own states와 observation를 기반으로 decision을 내린다. curse of dimenstionality를 극복하고 안전한 거리를 유지하기 위해 multi-level 정보를 사용하여 mean-field RL approach를 사용한다.
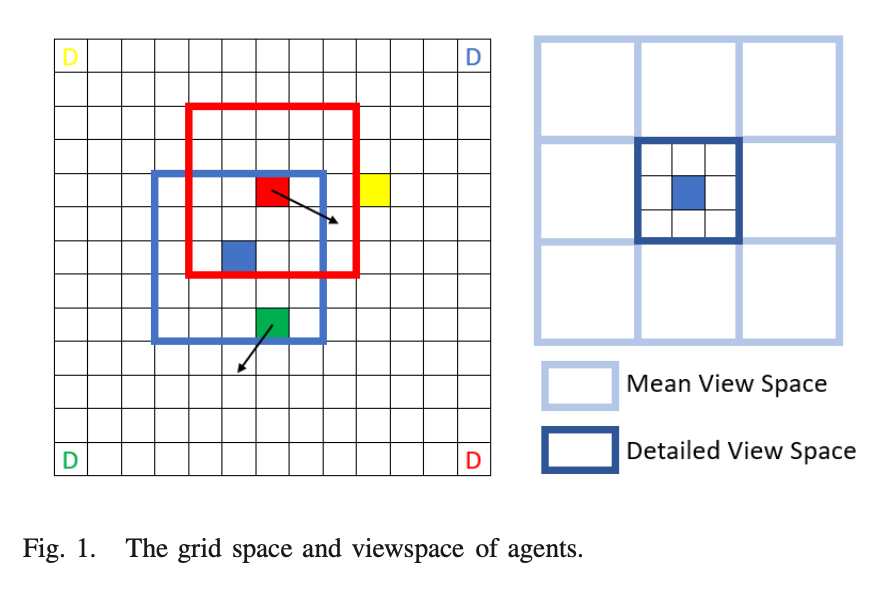
- 각 agent는 realative position, velocity, destination direction, neighbors in space(called intruders)에 대한 정확한 정보를 가지고 있고, view space 외부에 있는 다른 agents에 대한 통계 정보를 갖는 local view space를 가지고 있다.
- 위 local observation를 기반으로 multi-resolution, multi-agent, mean-field RL algorithm을 제안했다. 특히 CNN과 actor-critic algorithm을 사용한다.
Problem formulation
Horizontal routing
: flight planning이라고도 불리는 2D space 위의 routing을 고려한다. 2D space를 grid로 discretize하고 s_i ∈ S는 L x L space에서 목적지에 대한 grid 상의 ith agent의 상대 위치를 나타낸다. local state 외에도, 각 time slot에서 view space에 대한 observation o_i ∈ O도 사용할 수 있다.
View space
: detailed view space는 가까이 있는 침입자를 피하기 위해 사용되며 mean view space는 agent가 혼잡한 영역을 피하는데 도움이 된다.
1. detailed view space
: agent와 가까운 영역으로, relative positions, heading directions, destination 같은 view space의 침입자에 대한 자세한 정보가 필요하다.
2. mean-field view space
: agent 영역 주변의 mean-field view space를 나타낸다. 각 meta grid에서 자세한 정보가 포함되지 않고, 침입자 수와 mean direction만 필요하다. mean direction과 함께 agent의 수는 해당 영역의 침입자의 flow를 나타낸다. 침입자의 수는 flow의 크기를 나타내며 mean direction은 flow의 방향을 나타낸다.
Reward function
: r_i(s_i, o_i)를 state s_i에서 ith agent의 reward로 정의하고 observation o_i를 사용한다. 여기서 d_i는 ith agent의 목적지이고, dist(·, ·)는 Euclidean distance이고, N(i)는 ith agent의 view space에 있는 agent set이다. c0, c1, c2, r는 positive constant이다.

- agent가 destination에 도착하면 positive reward가, 그렇지 않다면 cost(negative reward)가 발생한다. cost는 세가지 구성 요소로 구성된다.
1. first component는 충돌이 감지되지 않으면 agent가 최단 경로를 따라 목적지를 향하도록 권장한다.
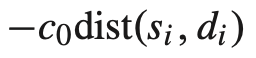
2. second component는 agent 간 안전을 위해 서로 거리를 유지하도록 권장한다.
: agent와 가까운 침입자는 안전상의 문제로 큰 cost를 발생시킨다. view space 밖의 침입자는 current cost를 변경하지 않지만 mean-field로 교육에 포함된다. 이를 통해 훈련 과정에서 multi-resolution을 구현한다.

3. third component는 constant이며 first & second component의 균형을 맞추는데 사용된다.
: model에서 중요한 역할을 하게된다.
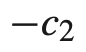
- 해당 문제에서 우리는 discounted total cost ∑ γ^t r_i (s_i(t),o_i(t))를 최소화 하기 위해 policy π(s_i ,o_i) : S x O → [0,1]를 최적화해야 한다.
3M-RL for UAV routing
Mean-field multi-agent RL
: agent's neighbor의 mean action과 own action으로 mean-field Q-value를 근사한다. Q^j는 agent j's Q-value이고, a는 모든 agents joint action, N(j)는 크기가 |N(j)|= N_j인 agent j's neighboring agent index set이다. a ̄j는 agent j's neighbor의 mean action이다.
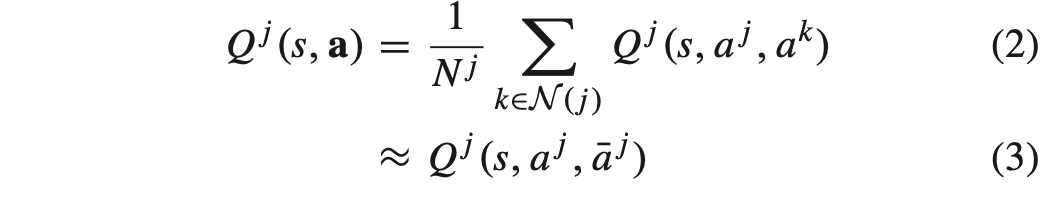
- neighbor area에 대한 mean observation 외에 각 agent는 view space의 침입자에 초점을 맞춘다. heading direction, destination of intruders in view space, detailed action과 같은 특징은 neighbor a ̄ j에서 사용된다. 이러한 정보는 observation o_j로 간주된다.
- mean view space도 필요하다. agent는 congested view space에서 침입자를 피할 수 없으므로 방지를 위해, mean direction을 사용한다.
3M-RL: Multi-Resolution, Multi-Agent, Mean-Field Actor Critic Algorithm
: actor-critic structure는 아래의 구조로 동작하며 학습의 variance를 줄이는데 도움이 된다. neighbors' mean action은 observation o_i에 포함되어 있다. 모든 agent가 own state, observation에 따라 결정을 내려 동작한다.
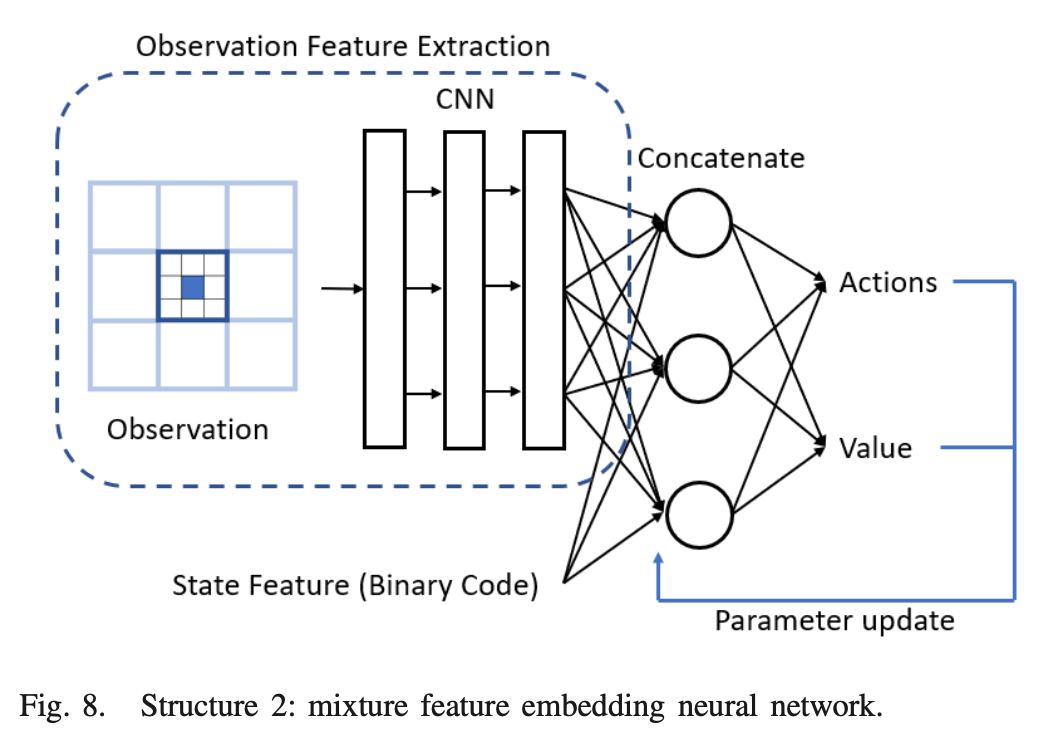
Mixture feature embedding NN
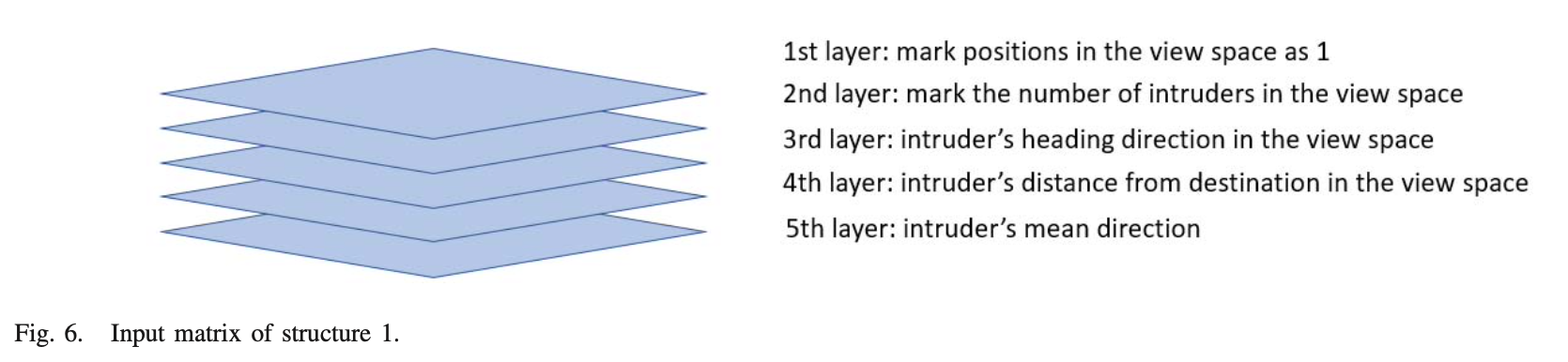
: agent's state와 observation이 이미지 형태로 쉽게 전송이 가능하고, π(s_i , o_i , θ) and vˆ(s_i, o_i, w)를 approximate 하기 위해 CNN을 사용한다. 해당 구조에서 CNN input은 view space와 크기가 동일한 3-layer matrix이다. matrix의 항목은 view space의 침임자 수, 침입자의 heading direction, 침입자의 distance from destination이다. 이러한 구조는 grid space의 크기가 증가함에 따라 신경망의 처리 시간을 크게 단축시킬 수 있다.
- CNN은 view space에서 observation feature를 추출하는데 사용된다. state feature는 state의 binary code이다.
- concatenate layer는 이러한 feature를 연결하는데 사용되며, output은 actor(action-value)와 critic(state-value)로 구성된다.
Continuous state space extension
: continuous state space env는 UAV ToolBox와 함께 MATLAB SIMULINK에 구축된다. 이 env에서 position은 더 이상 integer가 아닌 임의의 지점이다. action도 이전 처럼 단순하지 않고, target roll angle turn set = {Left − Left, Left, Maintain, Right, Right - Right}로 변경된다.
- state 및 observation 정보도 확장 되어야 한다. mixed feature embedding NN 구조가 사용되었으며, state feature vector에 agent's heading direction을 포함한다. 또한 observation matrix의 세 번째 layer도 continuous heading direction에 맞게 조정되었다.
Continuous 3D state space extension
: 2D보다 state space가 훨씬 더 큰 3D space에서의 collision-free path planning problem 또한 고려한다. 2D space에서와 달리 agent는 수평 및 수직 방향에서 서로 다른 model equation을 가지고 있다. 결과적으로 서로 다른 direction에서 turning radius와 sensitivity가 다를 수 있다.
- 3D space에서의 reward function은 다음과 같이 정의된다. dist function은 3D space에서의 거리고, 1은 indicate function이다. 또한 일부 application에서 UAV를 높이면 더 많은 energy cost가 발생하므로 action preference를 제어하는 데 사용되는 reward component r(a_i)를 도입했다.
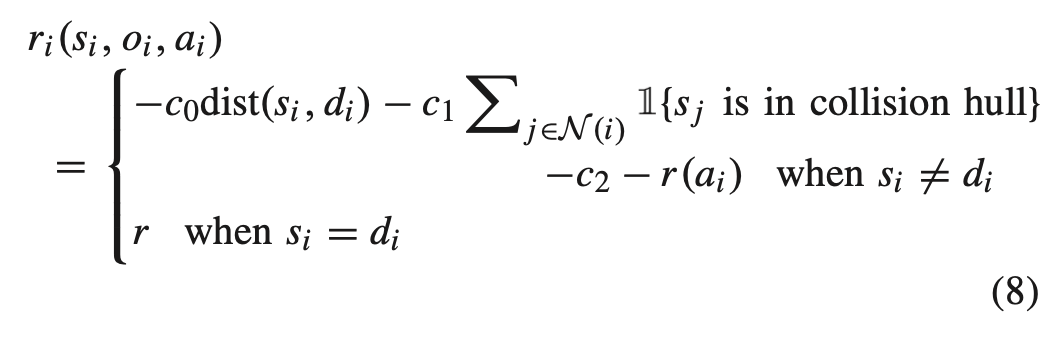
- model을 단순화 하기 위해 agent의 action space를 아래와 같이 정의한다.
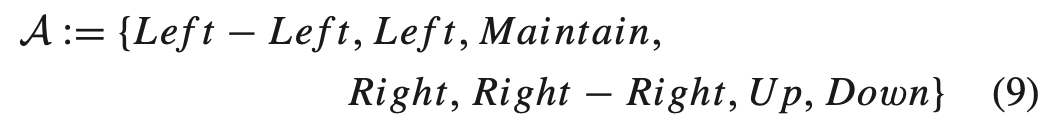
- HA는 heading angle의 변화, RD는 height의 상승 또는 하강이며, 이러한 action이 하나의 time slot보다 빨리 완료되었다고 가정한다.
- CNN 또한 3D CNN으로 대체하고 input은 4D matrix(width × length × height × information length)이다. 실험에서는 5 information length를 사용하였다. 3D observation에서의 detailed view space와 mean view space는 아래와 같다.
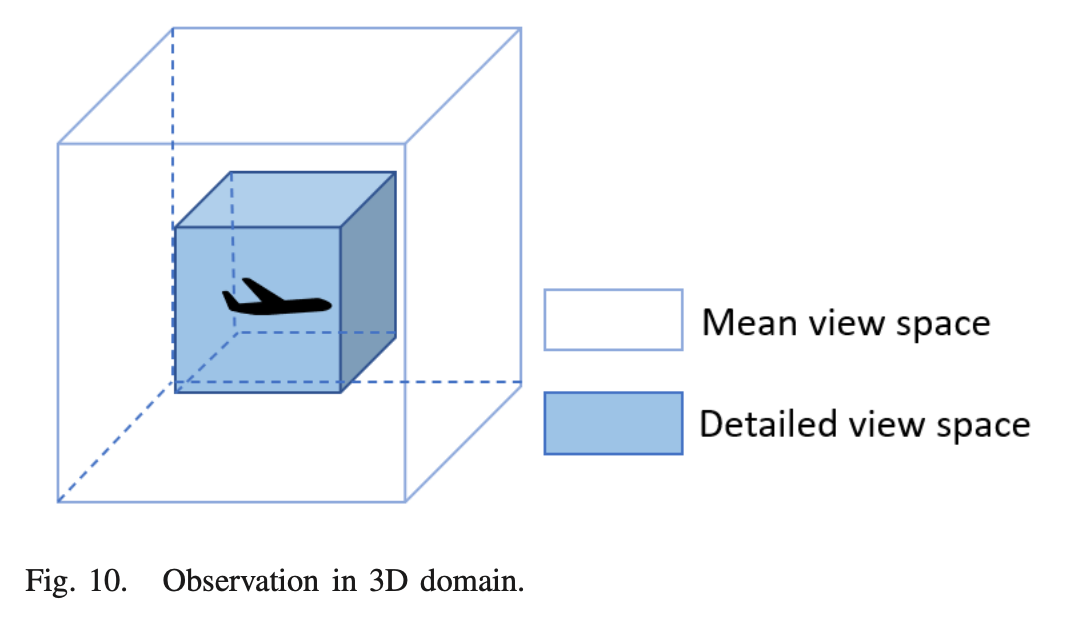
→ CNN과 mean-field를 사용한 detailed & mean view space에 대한 Q-value를 output한다. 이는 discrete state space 뿐만 아니라 continuous state space 및 3D env로 확장 가능하다.
3M-RL algorithm

→ 기존의 actor-critic structure를 사용하는 대신, input에 다양한 state로 각각의 feature를 추출하여 전달하는 CNN과 detailed view space, mean-field를 사용한 mean view space에서 mean action을 근사하여 Q-value를 output한다.
3M-RL results
: 3M-RL을 각 10 x 10, 20 x 20, 50 x 50 grid와 MATLAB & SIMULINK의 UAVToolBox에 구축된 continuous env에서 평가한다. 실험에 사용된 policy는 Boltzman distribution을 따르는 greedy policy이므로, testing policy는 determinisitc하다.
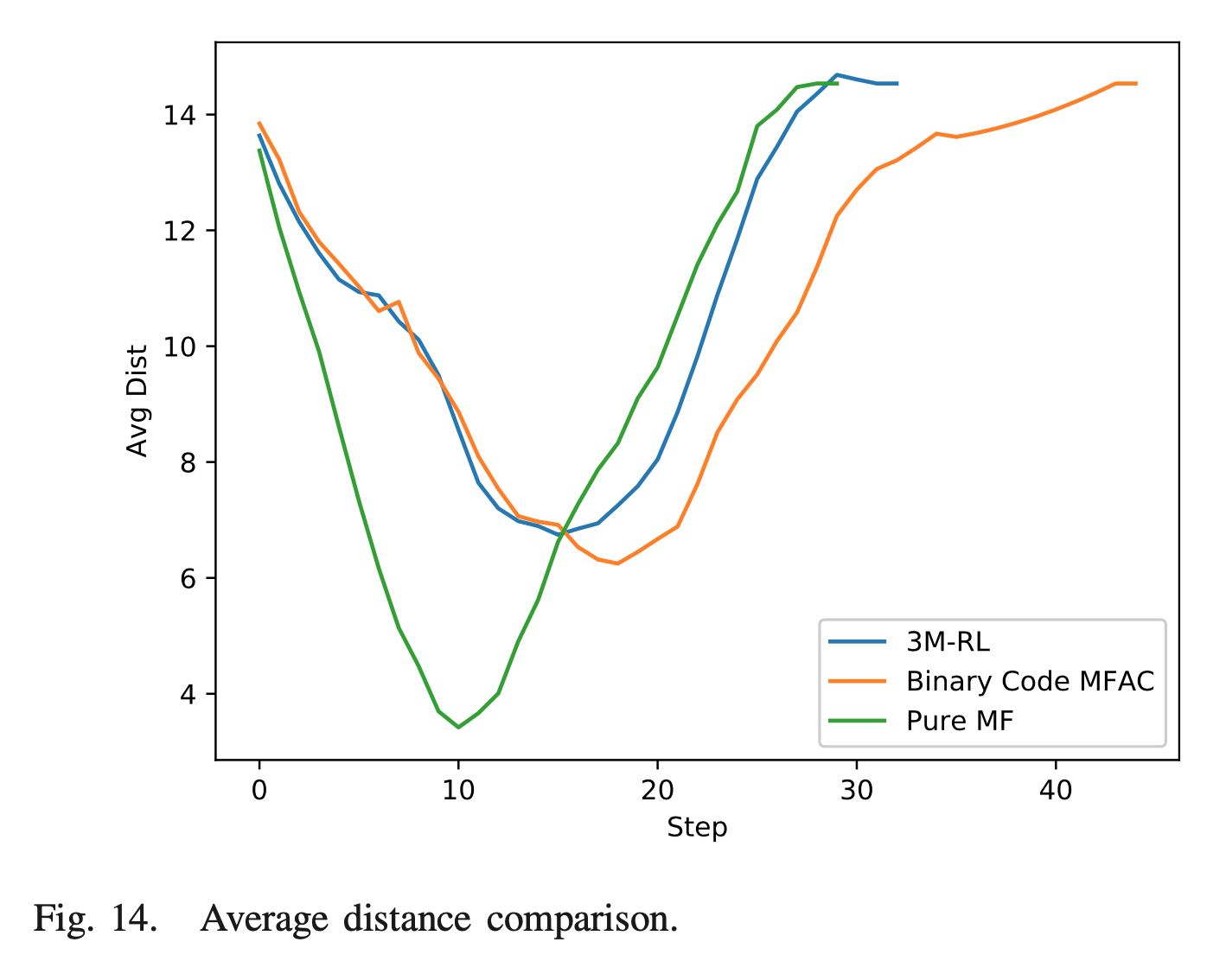
- Pure Mean-Field, Mean-Field Q-learning과 비교했을 때, 가장 빠른 convergence 속도와 optimal에 가까운 낮은 cost에 근접했다.
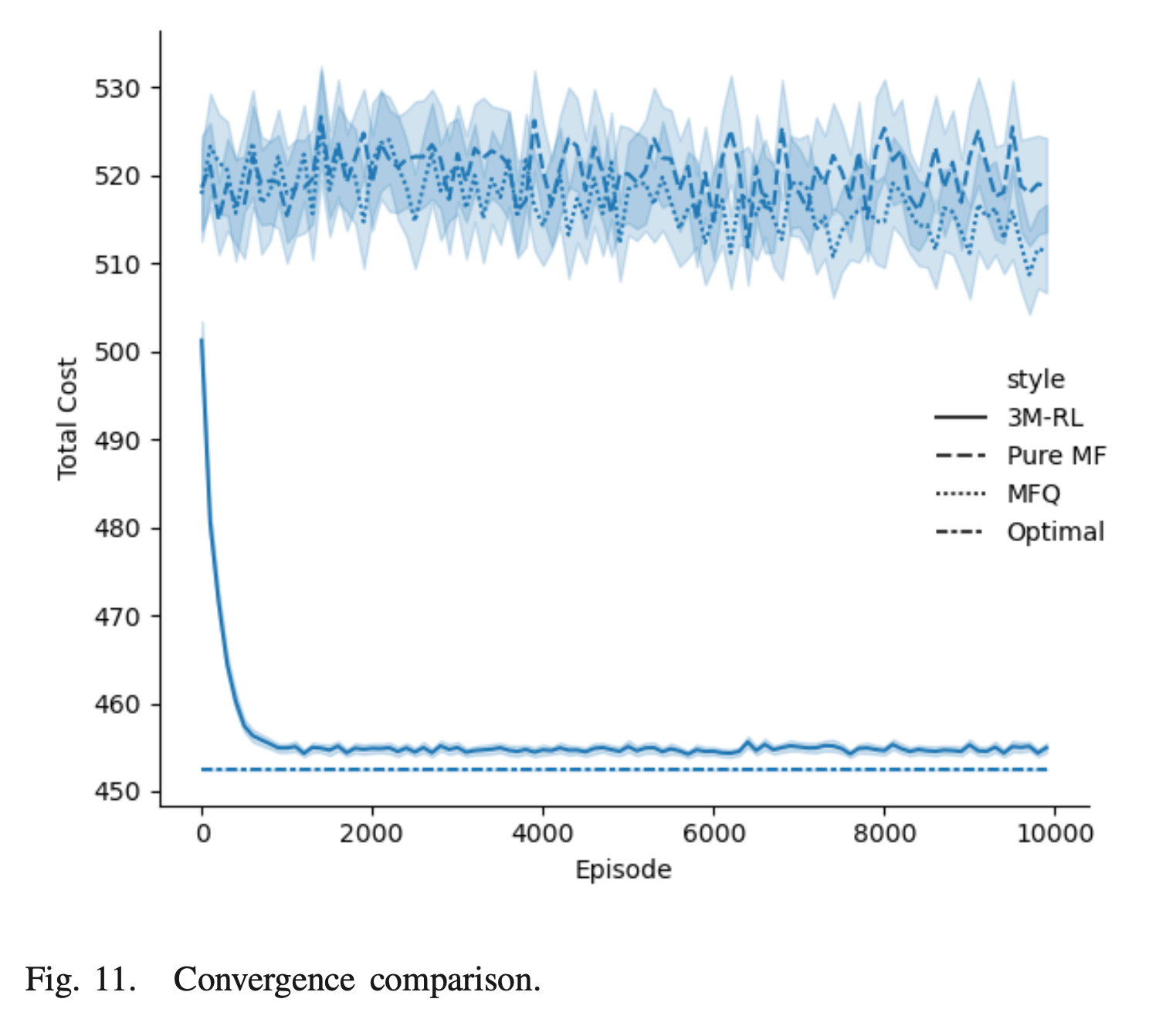
- c2의 유무에 따른 비교를 진행해본 결과, reward function을 balancing하는 c2가 없을 시에 충돌이 발생했다.
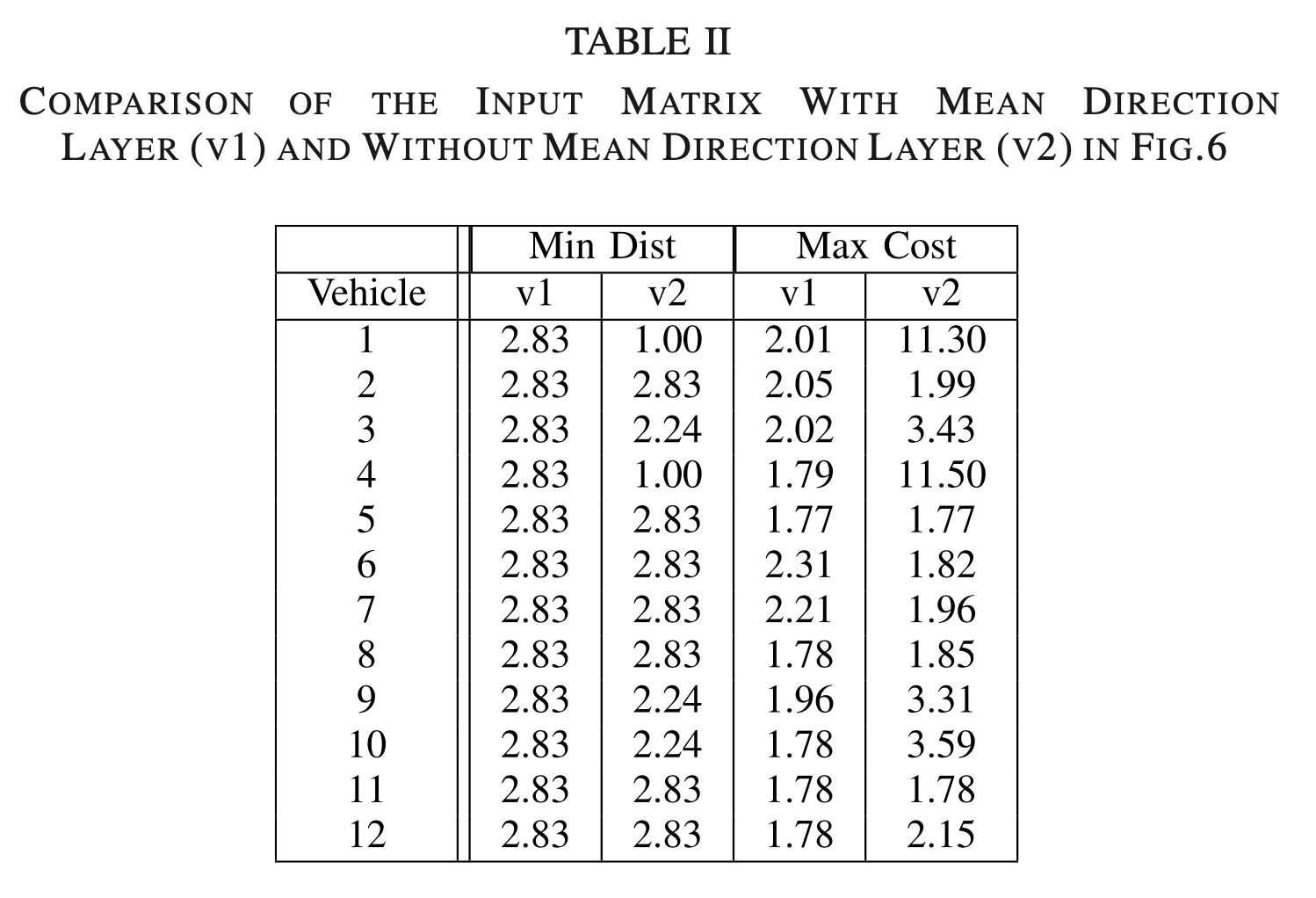
- Mean view space의 중요성을 확인해보면, mean direction layer를 사용하면 agent의 safety distance가 더 우수함을 볼 수 있다. input matrix의 5th layer가 없으면 max cost가 더 큰 variance를 겪게 되는데, 이는 episode 중에 약간의 congestion이 있음을 의미한다.
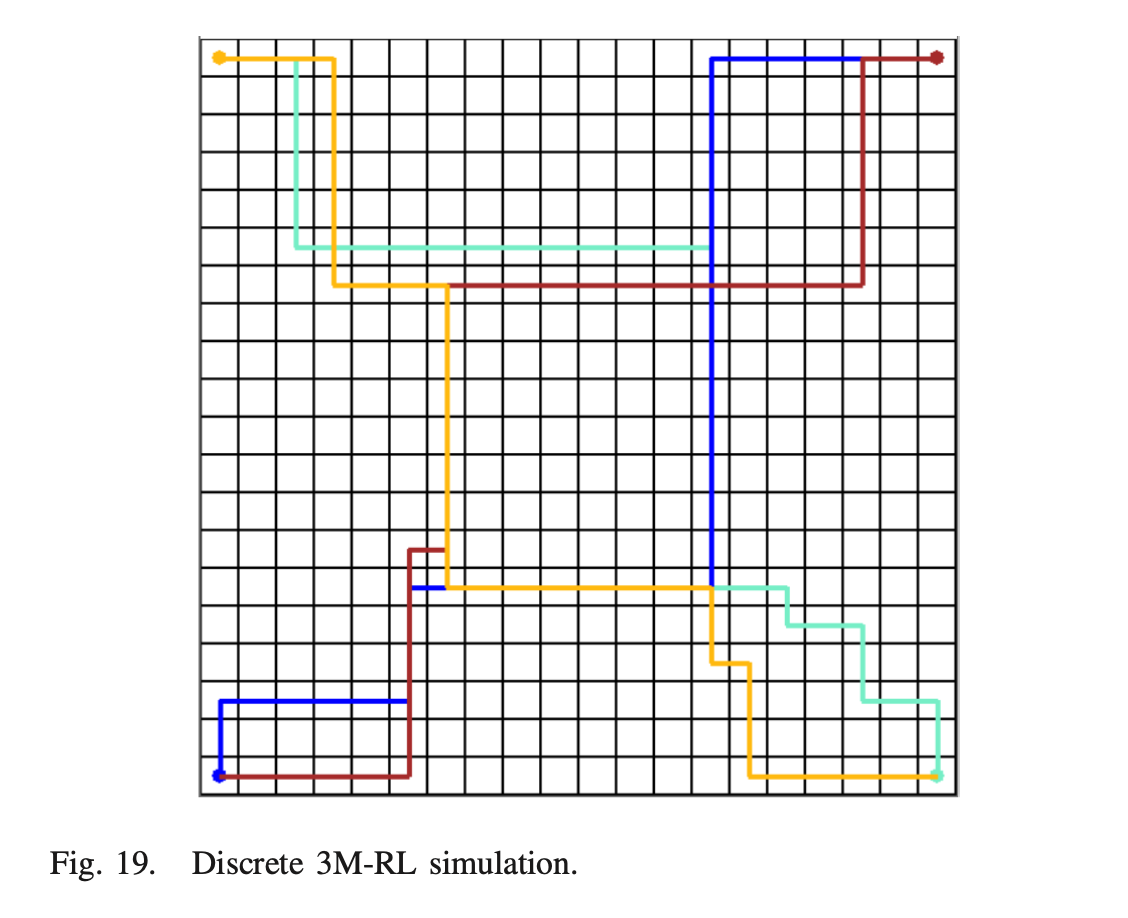
- Algorithm의 robustness을 테스트 하기 위해, 12개의 UAV 중 2개가 제거될 때의 policy는 대부분의 trajectories가 동일하게 유지되는 것으로 나타났다.
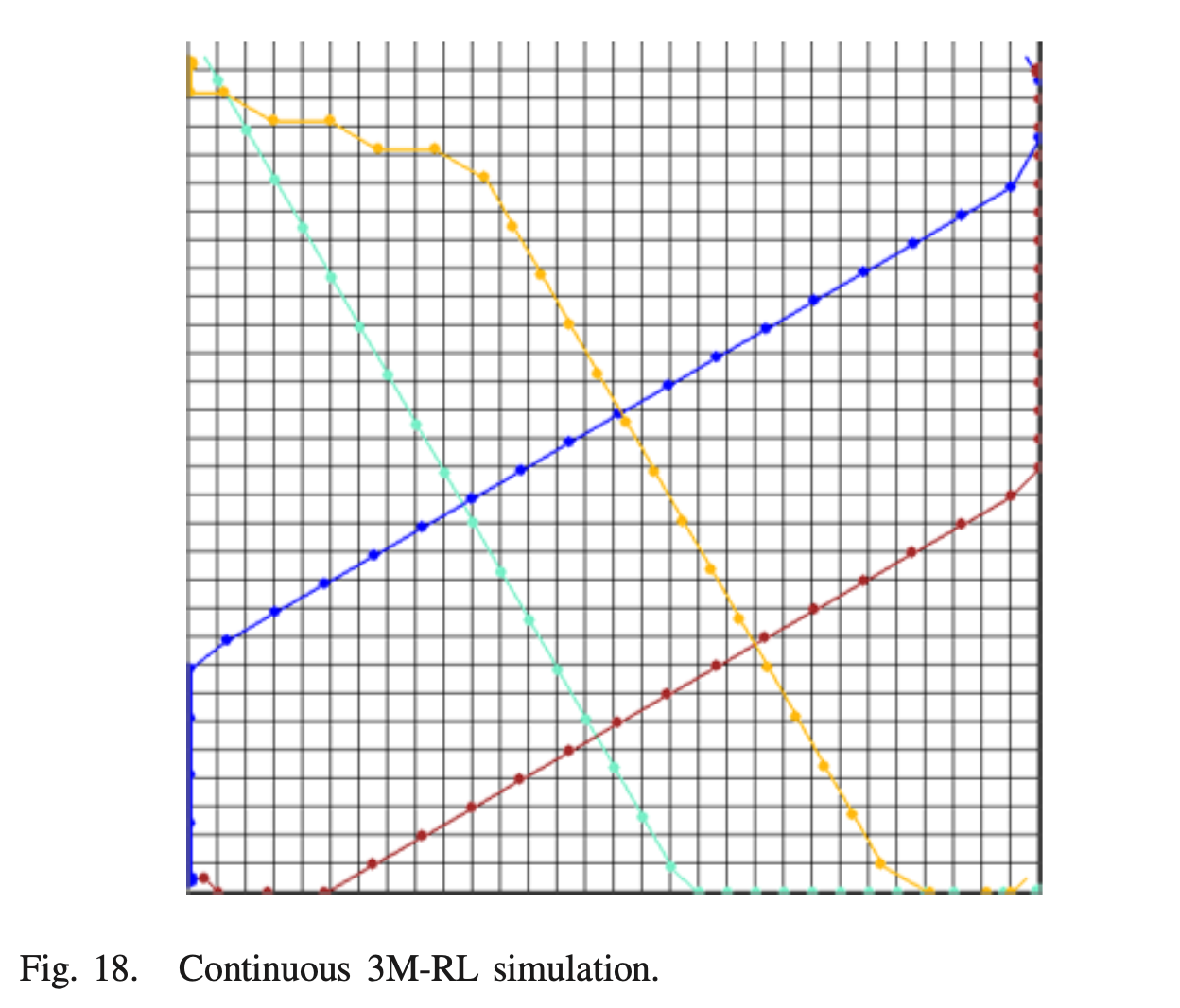
Continuous space simulation
: env는 시간적으로 discrete, state space에서 continuous, action space에서 discrete하게 설정된다. action은 1초마다 이루어지며 미리 정의된 target roll angle이다. 문제의 단순화를 위해 UAV speed는 항상 동일하게 유지된다. 빈번한 급격한 회전을 방지하기 위해 회전 action에 약간의 패널티도 부여한다.
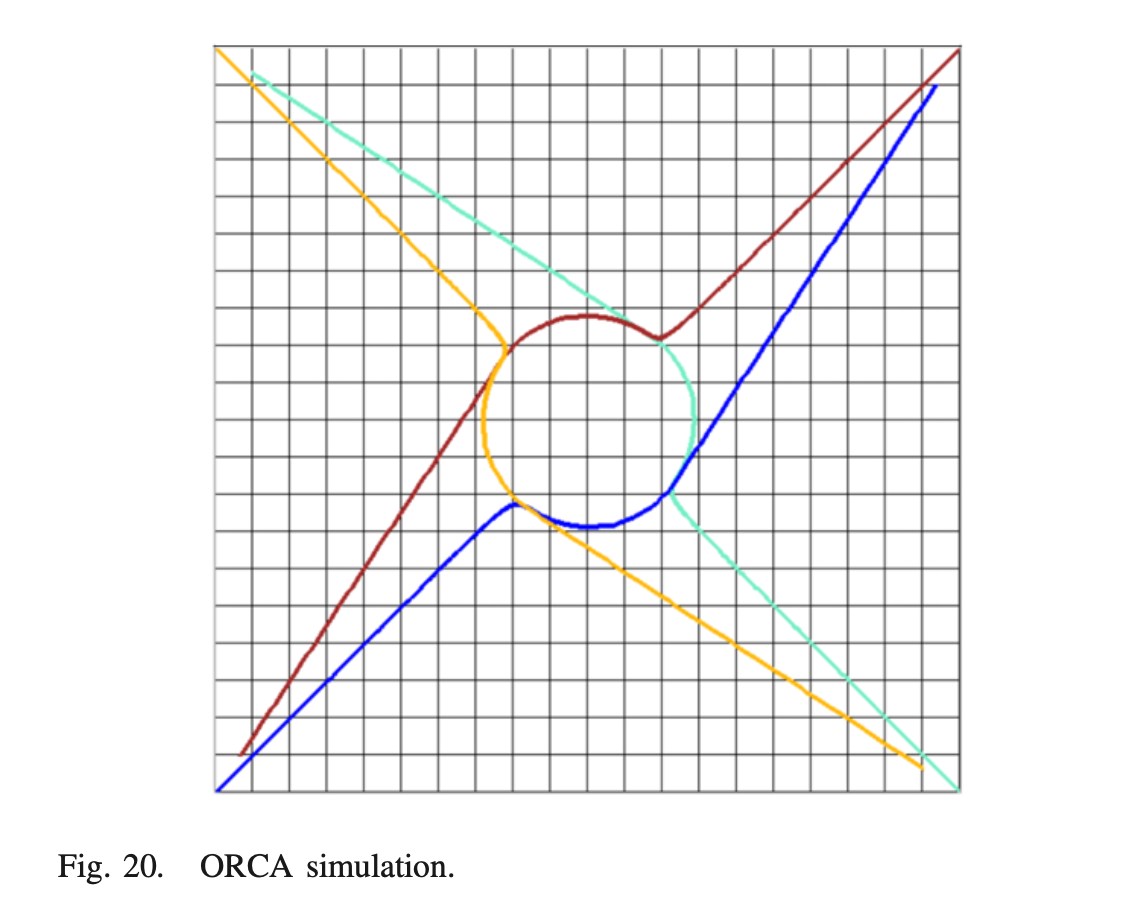
- 침입자가 '감지주기'에 나타날 때, agent가 방향을 변경하는 heuristic algorith인 ORCA(Optimal Reciprocal Collision Avoidance)와 비교한 결과 급격한 선회가 자주 발생하였으며, continuous 3M-RL은 학습 중 view space에 침입자가 들어갈 확률을 고려하여 보다 부드러운 trajectory를 얻을 수 있다.
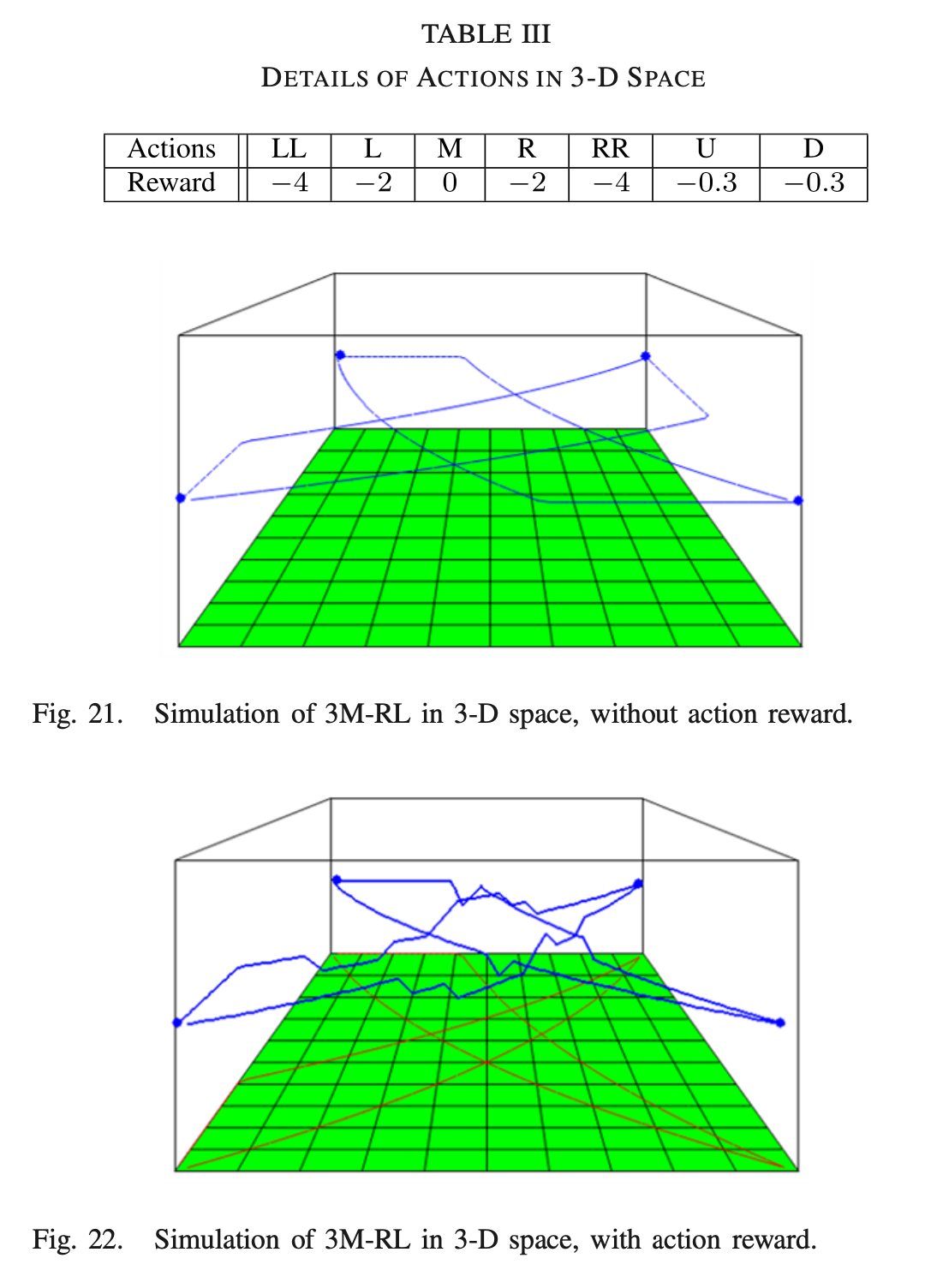
3D scenario simulations
: 3D space에서 collision avoidance를 고려하더라도 action reward 없이 진행한 결과 collision은 없지만 trajectory는 여전히 수평면에 있다. action reward를 적용한 결과 UAV가 높이가 다른 collision을 피할 수 있다.
Conclusion
: 해당 논문에서는 collision free UAV routing을 위한 3M-RL을 제안하고 CNN 및 actor-critic을 사용하여 algorithm을 구현하였다. 이는 cures of dimensionality를 극복하고 centralized path planning algorithm과 비교하여 compuiational complexity를 크게 줄인다. 그러나 UAV system 간 communication은 일반적으로 unreliable하며 일반적으로 delay와 loss가 발생하므로 이러한 문제 또한 고려하여 collision-free를 해결하는 방법이 필요해 보인다.
'논문 리뷰 > RL application' 카테고리의 다른 글
| Collaborative Multi-Agent Reinforcement Learning Aided Resource Allocation for UAV Anti-Jamming Communication (0) | 2022.08.26 |
|---|---|
| [MASCO] Coordination of EV Charging Through MARL (0) | 2022.07.13 |
댓글