목차
IEEE INTERNET OF THINGS JOURNAL: DOI 10.1109/JIOT.2022.3188833
Abstract
: UAV network에 대한 joint channel 및 power allocation에 대한 anti-jamming problem을 연구한다. 특히, UAV 간의 mutual interference와 external malicious jamming을 모두 방지하여 전력 소비와 관련된 시스템 경험 품질(QoE)를 극대화하는데 중점을 둔다. 해당 논문에서는 collaborate MALQL(multi-agent layered Q-learning) 기반 anti-jamming communication algorithm을 제안한다.
Introduction
: 해당 논문에서는 UAV network에서 joint channel과 power allocation에 대한 collaborative anti-jamming framework를 제안한다. 세부적으로는 UAV-UAV 간 collaboration과 competition을 동시에 고려하는 communication에 초점을 맞춘다. main contribution은 다음과 같다.
1. QoE(system quality of experience)를 최대화 하는 optimization problem을 formulate한다.
: Channel design과 power allocation 전략 형성을 통해 anti-jamming UAV network에서 power consumption을 고려한다.
2. Distributed manner로 UAV 간 collaboration과 competition을 알기 위해 optimization prove가 필요하다.
: 하나 이상의 pure strategy nash equilibrium을 허용하는 exact potential game으로 증명한 다음, local interactive game을 기반으로 각 agent에 대한 reward function을 재설계한다.
3. Formulated problem을 기반으로 collaborate MALQL(multi-agent layered Q-learning)를 제안한다.
: Convergence speed 가속과 각 agent의 action dimension을 감소시키는 anti-jamming communication algorithm이다.
System model
: N UAV pairs와 K jammers로 구성된 UAV network를 고려한다. UAV pairs는 제한된 지역 안에 랜덤하게 같은 높이 H로deployed된다. 각 UAV pair n에서는 transmitter n^tran와 receiver n^rec가 각각 존재한다. 이 때, 각 UAV pair에는 하나의 channel만 할당될 수 있고, jammer와 동일한 channel set를 공유한다고 가정한다.

- System은 discrete time slot에서 동작하며, UAV는 아래의 순서대로 spectrum sensing, learning and decision making을 수행한다.
① Channel을 spectrum sensing을 수행한다.
② Sensing result로 transmit channel과 power를 결정한다.
③ Selected channel에 decided power로 전송한다.
④ 전송 이후, UAV pairs는 communication results를 받고, 다음 position에게 새로운 communication을 보낼 준비를 한다.
→ 일반성을 위하여, UAV pairs와 jammers의 동작이 asynchronous하다고 가정한다. 따라서 sensing result와 전송 중에 UAV가 겪는 jamming channel은 다를 수 있다.
- UAV의 mobility는 Gauss-Markov mobility model을 고려하며 flight trajectories는 predisigned 되어있다. 이러한 환경에서, 3-dimensional location을 사용하게 된다. 이 때, UAV pair n에서 transmitter n^tran의 flight trajectory는 아래와 같이 표기된다.
- UAV pair n에서 transmitter n^tran과 receiver u^rec의 Euclidean distance 는 아래와 같다. 만약 u = n이면, UAV pair n에서의 internal distance를 의미한다.
Inference model
: 해당 논문에서는 graph based interference model를 사용하여 UAV network 내 transmission 혹은 interference를 측정했다. 각 UAV는 하나의 node로 취급된다.

- UAV pair n이 channel c_n(t)와 trasmit power P_n(t)를 time-slot t에서 선택한다고 가정한다. UAV pair n이 time-slot t에서 communication 시 수신된 inference와 jamming은 다음과 같이 표현된다. 이 때, I^uav_n(t)은 UAV pair과의 mutual co-channel interference를, I^jam_n(t)는 external malicious jamming을 의미한다.

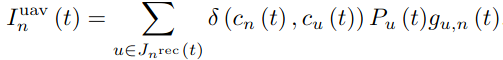

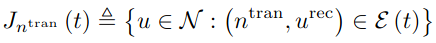

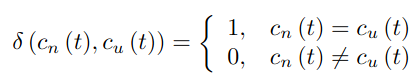

Communication model
: Interference model에 기반하여 achievable rate Rate(t)은 아래와 같이 표현된다. 이 때, N_0는 Gaussian noise power이다.
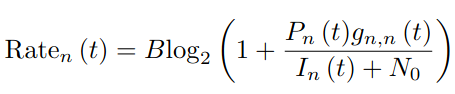
- 만약 이 값이 threshold Rate_n보다 클 경우에만 communication이 성공적으로 진행된다.
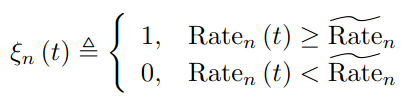
- Achievable rate와 rate threshold와의 gap을 측정하기 위해 QoE function을 사용한다. A_n, B_n, D_n은 QoE function의 value range를 결정하고, C_n은 function curve의 slope를 결정하는 모두 UAV pair n에 관련된 parameters이다.
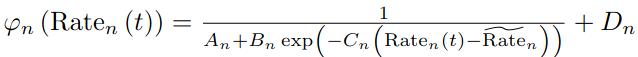
Local interaction markov game for multi-UAV networks
Problem formulation
: Global objective는 network QoE function을 최대화하고 power consumption을 동시에 최소화하는 optimal joint channel과 power allocation strategy를 찾는 것이다.
- 해당 논문에서는 model에서 power가 Y level로 분리되는 discretization을 고려한다. UAV pair n의 power는 아래와 같이 정의된다.
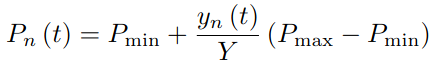

- 결과적으로 optimization problem은 아래로 정의된다.

위해 QoE function을 사용한다. A_n, B_n, D_n은 QoE function의 value range를 결정하고, C_n은 function curve의 slope를 결정
Local interaction markov game
: Problem P1을 풀기 위해서는 모든 agent의 정보를 알아야 하지만, 이는 computing cost가 너무 크기 때문에 problem을 local interaction Markov game으로 분해하여 재구성한다. 즉, UAV 간의 local interactions만 고려하여 학습을 진행한다. 아래는 local interaction이 어떻게 정의되는지 보여준다.


: state space는 UAV pairs-neighbors transmit이 성공적으로 되었는지에 대한 indicator와 sensing result u_k(t)를 포함한다.


: action space는 channel selection과 power decision으로 정의된다.

: E는 set of edge를 나타내며, edge로 연결되어 있다는 것은 서로 neighbor이라는 의미이다.


Reward design for cooperation among UAV pairs
: 기존 game model에서 agents들이 selfish하게 행동하는 방식은 global optimization을 보장할 수 없다. 그러나 individual maximization을 통해 system 극대화를 하기 위해, 해당 논문에서는 biographical system에서 local cooperation에 의해 motivate된 local altruistic behavior를 고려한다.
- 아래의 각 player n에서의 reward function은 own QoE, transmit power, aggregated QoE of its neighboring receivers 3가지 파트로 구성된다. 여기서는 각 agent에서 측정되는 expected average long-term reward를 채택한다.
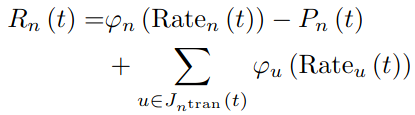
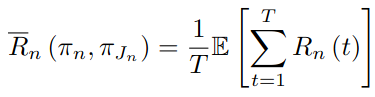
- Problem P1은 위에서 재정의한 reward function과 더불어 local altruistic game으로 modeling 하면 다음과 같이 표현이 가능하다.
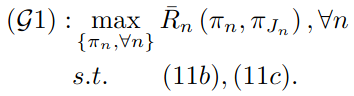
→ Local cooperation을 보장을 위해 problem P1을 local altruistic game model G1으로 분해한다. 분해 후, inference model, communication model을 고려한 individual agent's reward function 대신, 해당 agent's neighbors를 고려한 expected average long-term reward를 사용한다.
Collaborative multi-agent anti-jamming algorithm
: Global optimization problem P1이 local optimization problem G1으로 변환이 가능하므로, G1은 P1의 optimal strategy로 볼 수 있다. modeled local interaction markov game을 기반으로, channel state와 jamming strategy로 인한 G1 해결을 위해 model-free MARL algorithm을 제안한다.
MALQL(Multi-Agent Layered Q-Learning) based anti-jamming communication algorithm
: UAV anti-jamming problem은 power allocation strategy가 channel allocation strategy에 영향을 받기 때문에 즉, different sub-games를 different layers로 풀 수 있다는 의미를 가지므로 2개의 sub-games로 분리된다.
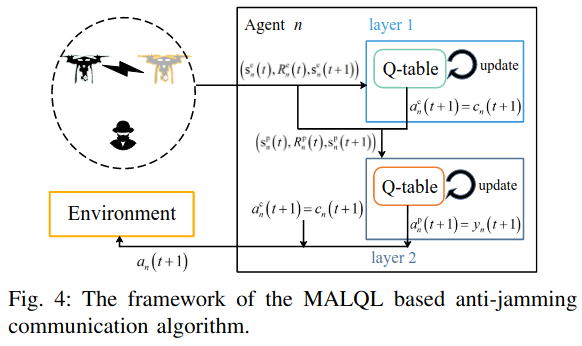
Layer 1
: agent n은 state s^c_n(t)에 따라 communication c_n(t)를 결정한다. 결과적으로, layer 1의 Q-table의 길이가 기존 multi-agent Q-learning보다 작다. 또한 우리는 channel selection sub-game을 first layer에서만 고려하면 된다.

- Agent가 optimal channel를 선택하면 optimal power decision이 내려질 수 있다. channel selection의 sub-game을 해결하려면 기존 reward function이 power selection 까지 연관되어 있기 때문에 재설계가 필요하다. 구체적으로, UAV pair n에 의해 선택된 channel은 jammer에 의해 jamming 되거나 neighboring UAV pair에 의해 선택되지 않는다.
- UAV가 다른 agent와 충돌하지 않고 channel을 선택하도록 권장된다는 사실을 고려하여 layer 1에서 사용될 reward function은 다음과 같다.

- 위 reward function에 따라서 layer 1의 Q-value는 아래와 같이 update된다.

Layer 2
: state는 아래의 s^p_n로 정의된다. agent n's channel choice는 tranmit power decision을 위해 layer 2로 extra state 정보로 추가된다.
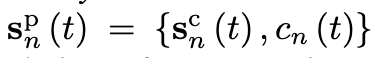
- agent n의 action 선택을 위해 layer 2의 reward function은 아래와 같이 정의된다. B는 R_n(t) - B ≤ 0을 만족하는 constant이다.

- 위 reward function에 따라서 layer 2의 Q-value는 아래와 같이 update된다.
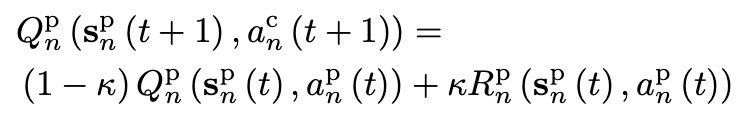
→ 기존 multi-agent Q-learning에서는 M x Y action space size를 가졌지만, 이러한 분할 방식을 통해 action space size는 M + Y로 축소시킬 수 있다.
MALQL algorithm
: 2개의 channel selection, transmit power decision을 위한 layer를 Q-learning method로 학습한다.

Performance evaluation
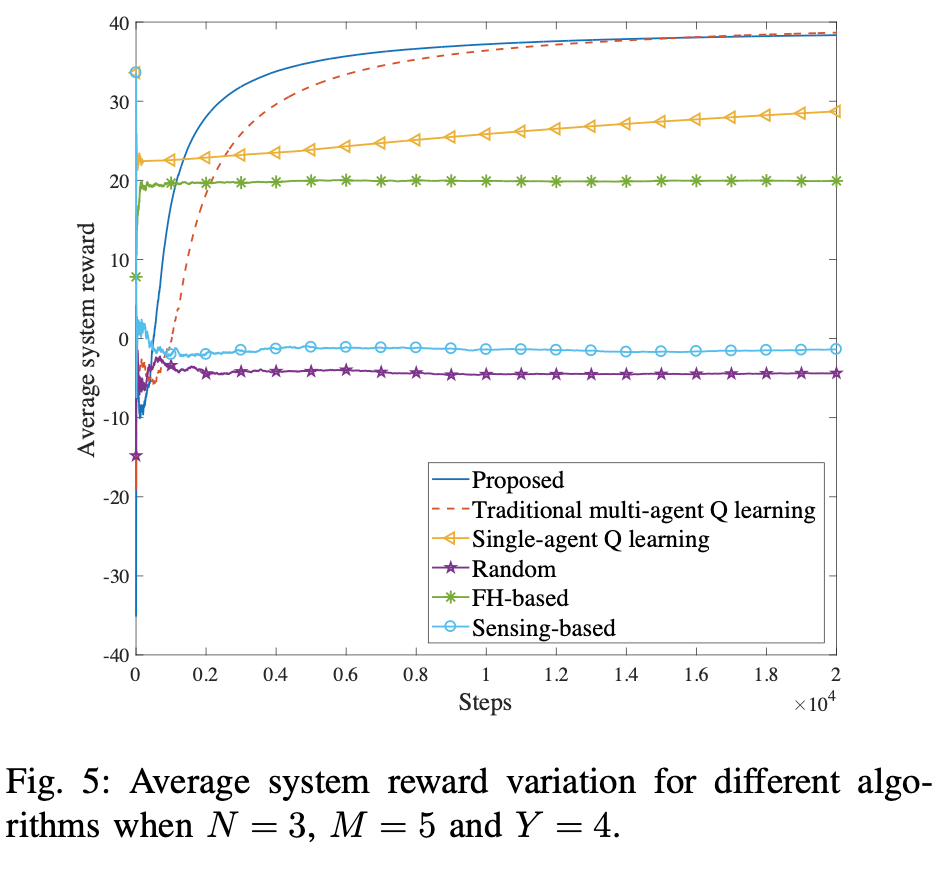
: 먼저 실험을 위한 simulation에 관련된 setting은 다음과 같다. performance 비교를 위해서 해당 논문에서는 single-agent Q-learning, traditional multi-agent Q-learning, random, frequency-hopping based method, sensing-based method를 사용한다.


- 제안된 MALQL algorithm은 가장 빠른 convergence speed와 explore 및 exploration efficiency에도 가장 적은 시간안에 수행이 가능했다.

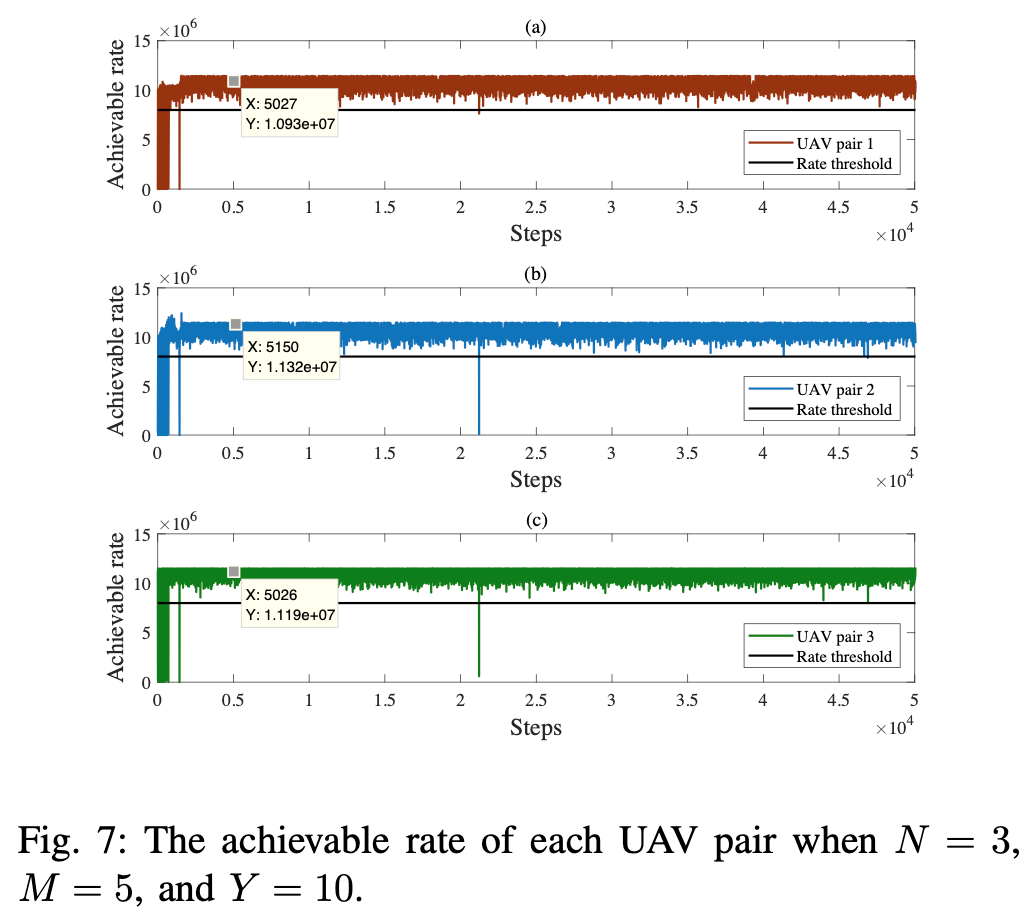
→ rate threshold를 달성하기 위해 적절한 transmit power를 선택할 수 있지만, channel gain이 나빠지면 중간중간 threshold를 넘기지 못하는 경우가 생기기도 한다.
- Initial step부터 convergence step까지 channel selection 변화 과정을 보여준다.

- channel 수와 power level 수에 대한 영향을 고려한다. channel 수가 증가함에 따라 평균 system reward가 증가하는 것을 알 수 있다. 그러나 channel 수가 7보다 크면 reward 개선은 미미하다. 다른 수의 power level을 채택할 때도 평균 reward 증가폭 또한 작다.

→ channel 수 또는 power level 수를 늘리면 action space가 증가하여 agent의 redundant exporation이 발생하게 되어 평균 system reward 상승이 미미하다. UAV pair의 수와 channel 수의 관계를 고려할 때, UAV pair의 수가 변경되면 해당 channel의 수도 변경되어야 함을 알 수 있고, 이상적으로는 'channel 수 - 2 = UAV pair 수'일 때, complexity와 performance의 균형을 맞출 수 있다.
- 아래 도표는 UAV pair의 power allocation policy에 대한 channel state 및 UAV receiver & jammer 사이의 거리의 영향을 나타낸다. UAV pair는 channel state가 나쁠 때, 거리에 따라 가장 낮은 power 또는 가장 높은 power를 선택한다.
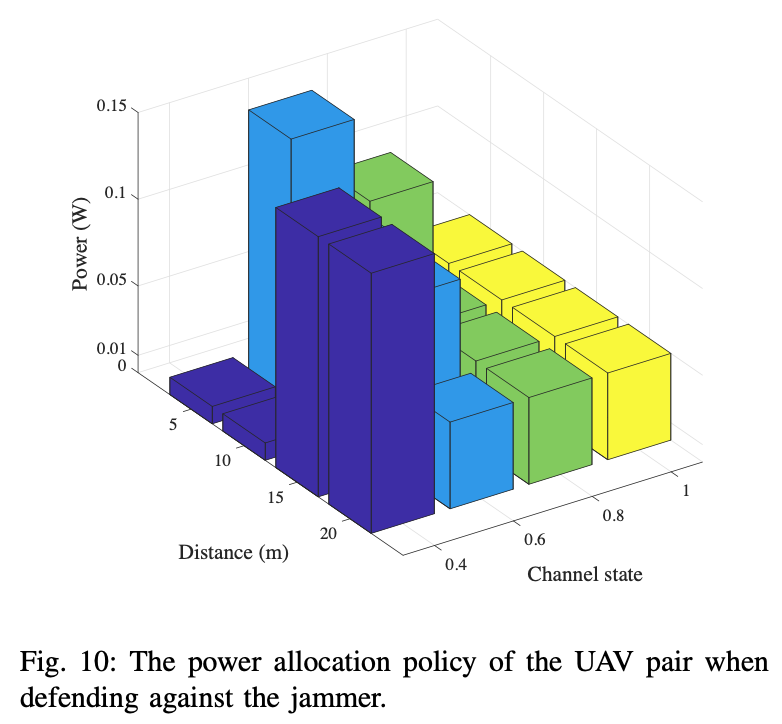
→ 근본적인 이유는 jammer가 UAV receiver에 너무 가까우면 UAV pair이 성공적으로 communicate 할 수 없고 power consumption을 줄이는 것 외에는 선택의 여지가 없기 때문이다. jammer가 UAV receiver로부터 멀리 떨어져 있으면 UAV pair는 성공적인 communication을 위해 가장 높은 power만 선택할 수 있다. channel state가 충분히 좋은 경우, UAV pair는 거리에 관계없이 jammer 대응을 위해 상대적으로 낮은 전력을 선택할 수 있다.
Conclusion
: 해당 논문에서는 optimal system QoE를 최대화하고, joint channel과 power allocation를 최소화 하기 위한 dynamic UAV anti-jamming algorithm을 제안한다. 이론적으로 anti-jamming problem의 NE existence가 증명된다. MALQL은 convergence speed 및 average performance에서 훨씬 우수한 성능을 타나낸다. 또한 intelligent jamming scenario에서도 강력한 practicability와 scalability를 보여준다.
'논문 리뷰 > RL application' 카테고리의 다른 글
| [3M-RL] Multi-Resolution, Multi-Agent, Mean-Field Reinforcement Learning for Autonomous UAV Routing (0) | 2022.08.13 |
|---|---|
| [MASCO] Coordination of EV Charging Through MARL (0) | 2022.07.13 |
댓글