NLP Methods
- Traditional RNN
- Attention Mechanism
Transformer Concept
- Encoder
- Decoder
Model Architecture
- Encoder & Decoder Stacks
- Attention
- Position-wise Feed-Forward Networks
- Embeddings and Softmax
- Positional Training
NLP Methods
Traditional RNN

: RNN은 문장에서 sequential하게 state-value를 계산하고 최종적으로 state-value를 context vector로 사용하게 된다. decoder는 이 context vector를 기반으로 <EOS>에 도달할 때까지 입력된 문장을 번역하게 된다.
그러나 context vector가 고정된 크기이기 때문에, 책과 같이 긴 문장의 입력인 경우 고정된 context vector에 문장의 모든 정보를 저장하기가 어려워 번역 결과가 좋지 않았다.
Attention mechanism
: 더 이상 고정된 크기의 context vector를 사용하지 않고, encoder의 모든 state-value를 사용한다. 단어를 하나씩 번역할 때마다 동적으로 encoder 출력값에 attention mechanism을 적용한다. 기존 encoder & decoder의 성능을 상당히 강화시켰다.
그러나 RNN cell을 순차적으로 계산하여 여전히 느리다는 단점이 존재했다.
Why Transformer is faster than RNN?
: RNN을 사용하지 않아, sequence computation을 감소시켰기 때문이다. RNN이 sequential하게 첫 번째 단어부터 마지막 단어까지 encoding하던 과정과는 다르게 parallelization을 사용한다. 즉, 병렬화를 통해 한번에 처리하는 방식을 사용하였다.
Transformer Concept
: RNN의 sequential computation 대신 matrix multiplication으로 한번에 처리한다. Transformer는 한 번의 연산으로 모든 중요정보를 각 단어에 encoding한다. 단어의 위치 및 순서 정보를 활용하던 RNN이 없는 Transformer는 positional encoding을 통해 단어의 위치를 파악한다.
Encoder
1) Positional encoding

: encoder 및 decoder 입력값마다 상대적인 위치 정보를 더해주는 방식이다. 위는 vector를 작은 연속된 상자로 표현한 상태에서 bit positional encoding 방식을 적용한 예제이다. 자세히 살펴보면 순서대로 i에는 001, study에는 010, at에는 011, school에는 100을 더해주었다. 같은 방식으로 decoder에도 적용이 가능하다.
Transformer에는 예제에서의 bit 방식은 아니지만 sin과 cos function을 활용한 positional encoding을 활용한다. 각 단어를 word embedding 하고 난 뒤, positional embedding을 각각 더해준다.
sin & cos function encoding advantage
1) 항상 positional encoding의 값은 -1과 1사이이다.
2) 모든 상대적인 positional encoding의 장점으로써, 학습 데이터 중 가장 긴 문장보다도 더 긴 문장이 실제 운용중에 들어와도 error 없이 positional encoding 값을 줄 수 있다.
2) Self Attention

: encoder에서 이루어지는 연산이다. query, key ,value는 matrix W_q, W_k, W_v에 의해서 생성되고, 이 matrix들은 단순히 weight matrix로 딥러닝 모델 학습과정을 통해 최적화된다. word embedding은 vector이고 실제 문장 전체는 matrix라고 할 수 있다. matrix는 matrix과 곱할 수 있으므로 각 문장에 있는 단어들의 query, key, value는 matrix multiplication을 통해 한번에 구할 수 있다.
query, key, value는 vector 형태이고, 이를 통해서 positional embedding 된 단어들에 대해 self attention을 수행할 수 있다.

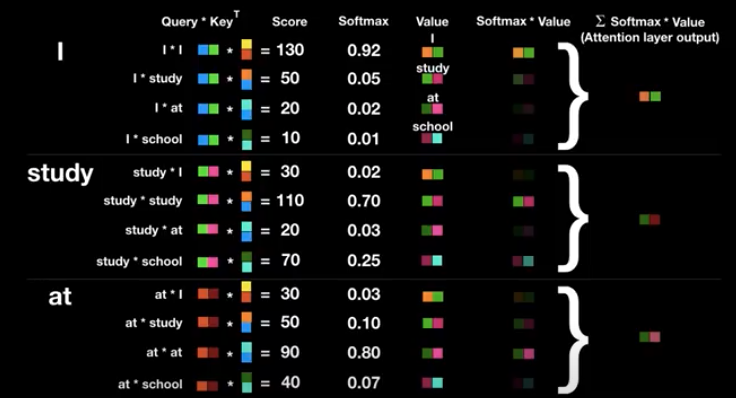
1) 현재의 단어는 query이고, 어떤 단어와의 상관관계를 구할 때 현재 단어를 다른 단어의 key에 곱해준다. 이 query와 key를 곱한 값을 attention score라고 부른다. query와 key가 모두 vector 이므로, dot product를 통해 곱할 경우 그 결과는 숫자로 나오게 된다.
2) attention score를 0부터 1까지의 확률 개념으로 바꾸기 위해 softmax를 적용하기 전에 논문에서는 √dimension of key vector로 나눠준다. key vector의 dimension이 늘어날 수록, dot product 계산 시 값이 증대되는 문제를 보완하기 위해서 이런 조치를 취했다고 한다.
3) softmax의 결과값은 key에 해당하는 단어의 현재 단어와의 연관성을 나타낸다.
4) softmax에서 나온 각 확률과 value를 곱해서 attention이 적용된 value들을 모두 더해준다.
결과로 나온 최종 vector는 단순히 단어 i가 아닌, 문장 속에서 단어 i가 지닌 전체적인 의미를 지닌 vector라고 간주된다.
입력 문장 전체는 matrix로 표현이 가능하고, key, value, query도 모두 matrix로 저장되어 있으므로 모두 단어에 대한 attention 연산은 matrix multiplication으로 한번에 처리가 가능하다. RNN을 사용하였다면, 처음단어부터 끝까지 순차적으로 계산했었어야 하지만 attention을 사용하여 병렬 처리를 가능하게 하였다.
3) Multi head Attention

: attention layer을 병렬로 동시에 수행한다. 사람의 문장은 모호할 때가 상당히 많고, 하나의 attention 과정으로 이 정보를 encoding 하기는 어렵기 때문에 multi-head attention을 사용하여 되도록 연관된 정보를 다른 관점에서 수집하여 이 점을 보완한다.
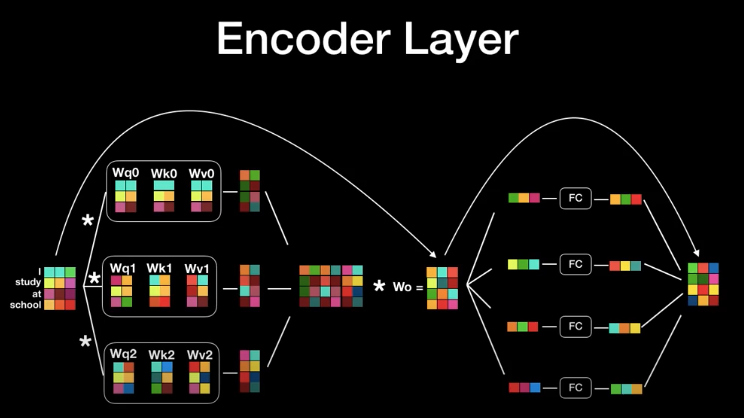
1) self attention으로 출력된 여러 결과값들을 multi-head attention에 이어붙인다.
2) 또 다른 행렬과 곱해져 최초 word embedding과 동일한 dimension을 갖는 vector로 출력된다.
3) 각각의 vector는 fully-connected layer로 들어가 input과 동일한 size의 vector로 출력된다. output vector의 차원의 크기가 input vector의 크기와 동일하다.
4) 딥러닝 시, back propagation에 의해 positional encoding이 손실될 수 있다. 이를 보완하기 위해, residual connection으로 입력된 값을 다시 한번 더 더해주는 방식을 사용한다.
5) residual connection 뒤에는 layer normalization을 통해서 학습의 효과를 증진시켰다.
위에서 언급한 output vector와 input vector의 크기가 동일하다는 것은 이러한 encoder layer 자체 또한 여러번 이어 붙일 수 있다는 의미이기도 하다. 실제로 Transformer에서는 이 encoder 6개를 연속적으로 붙여서 사용하는 구조를 취한다. 각각의 encoder는 weight를 공유하지않고 개별적으로 유지하며, 최종 encoder의 결과는 6번째 encoder layer의 결과이다.
Decoder
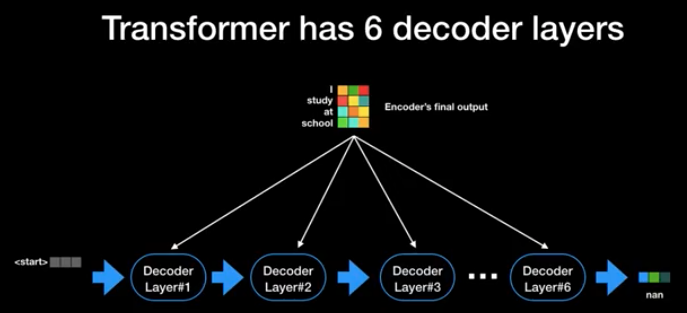
: encoder과 동일하게 6개의 layer를 사용한다. decoder 역시 병렬처리를 활용한다.
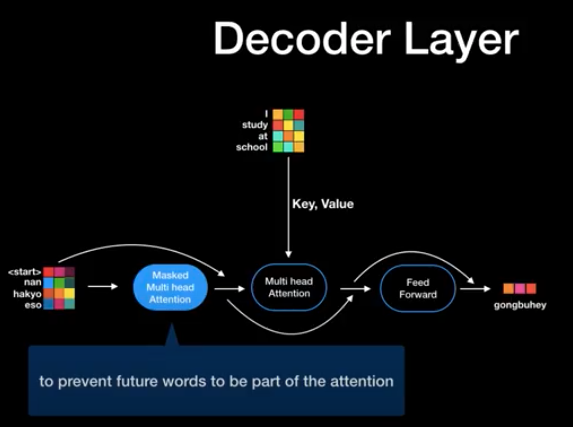
: decoder layer에서 아직 출력되지 않은 미래의 단어에 적용하지 않고 현재까지 출력된 값들에만 attention을 적용하기 위한 masked multi-head attention layer를 가진다.
1) encoder과 같이 query, key, value를 가진다. 큰 차이점은 이전 decoder의 상태는 encode에 질문하는 query로 ,encoder의 최종 출력 값을 key, value로 사용한다.
2) decoder 밑단에는 softmax의 입력값을 생성할 logit을 만드는 linear layer와 모델이 알고있는 모든 단어들에 대한 확률 값을 출력하는 softmax layer가 존재한다.
3) Transformer에서는 최종 단계에서도 label smoothing을 사용하여 기존의 one-hot encoding output이 아닌, 0 또는 1이 아닌 가까운 값들만을 사용하는 표현을 사용하였다. label이 명확한 경우에는 의미가 없을지 모르지만, label이 noisy한 경우, 즉 같은 input에 대해 다른 output이 나오는 경우 큰 도움이 되는 방식이다.
Model Architecture
대부분의 competitive neural sequence tranduction model은 encoder-decoder structure를 사용한다. input sequence of symbol representations (x_1, ... , x_n)를 continuous representations z = (z_1, ... , z_n)에 매핑시킨다. z가 주어지면 decoder는 한 번에 한 element씩 symbol의 output sequence (y1, ... , y_m)을 생성한다. 각 단계에서 model은 auto-regressive하며 다음을 생성할 때 이전에 생성된 symbol representation을 추가 input으로 사용한다.
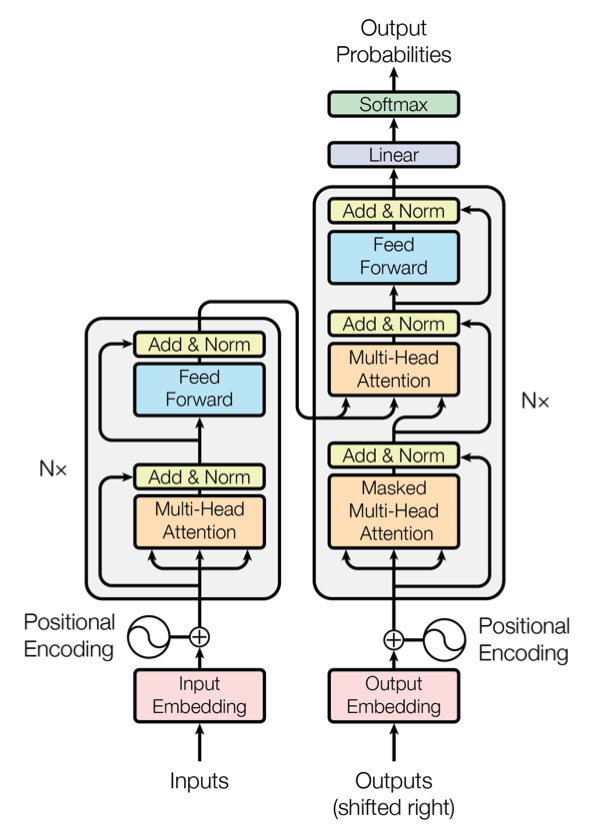
: Transformer는 각각 위 그림의 왼쪽과 오른쪽 절반에 표시된 encoder와 decoder 모두에 대해 stacked self-attention, point-wise, fully-connected layers를 사용하여 architecture를 구성한다.
1) Encoder and Decoder Stacks
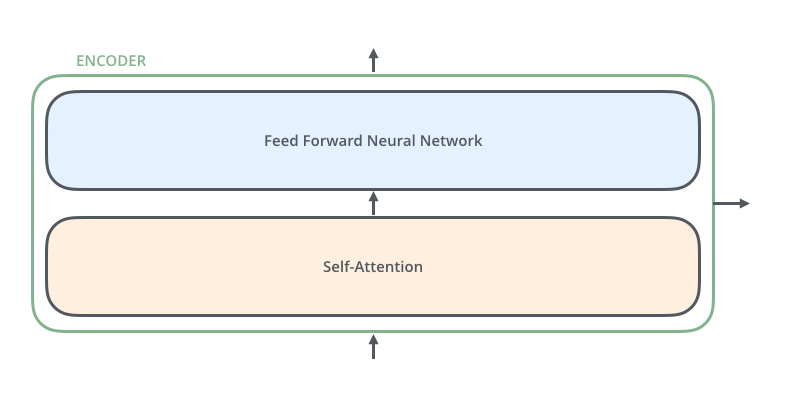
Encoder
: encoder는 N = 6개의 동일한 layer stack으로 구성된다. 각 layer에는 두 개의 sub-layer가 있다. 그 중 첫 번째는 multi-head self-attention mechanism이고 두 번째는 simple, position-wise fully connected feed-forward network이다. 이 두 sub-layer 각각 주위에 residual connection을 사용하고 layer normalization을 수행한다.
residual connection
즉, 각 sub-layer의 output은 LayerNorm(x + SubLayer(x))이며, 여기서 SubLayer(x)는 sub-layer 자체에서 구현하는 기능이다. 이러한 residual connection을 용이하게 하기 위해 model의 모든 sub-layer과 embedding layer는 동일한 d_model = 512의 output dimension을 생성한다.
Decoder
: decoder도 N = 6개의 동일한 layer stack으로 구성된다. 각 encoder layer의 두 sub-layer 외에도, encoder stack의 output에 대해 multi-head attention을 수행하는 세 번째 sub-layer을 삽입한다. encoder와 유사하게 각 sub-layer 주위에 residual connections을 사용하고 layer normalization을 수행한다. 또한 decoder stack의 self-attention sub-layer를 수정하여 present positions가 subsequent positions에 attending하지 못하게 한다. output embedding이 one position만큼 offset된다는 사실에 기반한 이 masking은 position i에 대한 prediction이 i보다 작은 position에서 알려진 outputs에만 의존할 수 있도록 보장한다.
2) Attention
위에서 encoder는 N = 6개의 layer들로 구성되어 있고, 모든 layer는 각각 두 개의 sub-layer를 가진다고 하였다.
Attention function은 query와 set of key-value pairs를 output에 매핑하는 것이라고 설명할 수 있다. 여기서 query, key, value, output은 모두 vector이다. output은 value의 weighted sum으로 계산되며, 여기서 각 value에 할당된 weight는 query & corresponding key function에 의해 계산된다.
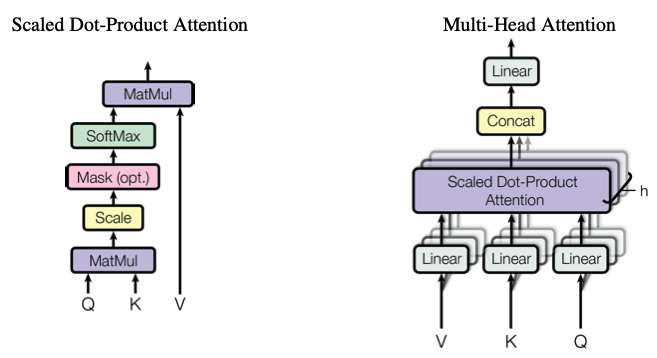
Scaled Dot-Product Attention(Self-Attention)
input은 query, keys of dimension d_k, values of dimension d_v로 구성된다. 모든 key로 query와 내적을 계산하고, 각각을 √d_k로 나누고, value에 대한 weights를 얻기 위해 softmax function을 적용한다.
실제로, query set에 대한 attention function을 동시에 계산하여, matrix Q로 묶는다. key와 value도 matrix K와 V로 묶인다. output matrix는 다음의 수식으로 계산한다.
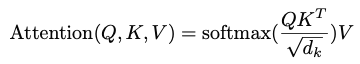
가장 일반적으로 사용되는 두 가지 attention function은 additive attention과 dot-product(multi-plicative) function이다.
Dot-product attention
: 1/√d_k의 scaling factor를 제외하고 Transformer algorithm과 동일하다.
Additive attention
: single hidden layer를 d_k로 하는 feed-forward network를 사용하여 compatibility function을 계산한다.
두 방식 모두 theoretical complexity는 유사하지만, dot-product attention은 최적화된 matrix multiplication code를 사용하여 구현할 수 있기 때문에 실제로 훨씬 빠르고 공간 효율적이다.
작은 d_k 값에 대해 두 메커니즘이 유사하게 수행되는 반면, additive mechanisms는 큰 d_k 값에 대한 scaling 없이 dot-product를 능가한다. 큰 d_k 값에 대해 dot-product는 크기가 크게 증가하여, softmax function을 매우 작은 grdient가 있는 영역으로 밀어넣는 것으로 의심된다. 이 효과를 상쇄하기 위해 dot-product를 1/√d_k만큼 scaling한다.
Multi-Head Attention
: d_model dimensional key, values, queries로 single attention function을 수행하는 대신, 각각 d_k, d_k 및 d_v 차원에 대해 학습된 서로 다른 linear projection으로 query, key, value를 h번 linear projection하는 것이 유익하다는 것을 발견했다. 이러한 각 projected versions of queries, keys, values에 대해 attention function을 병렬로 수행하여 d_v 차원의 output value를 생성한다. 이것들을 연결되고 다시 한번 project되어 최종 값이 된다. multi-head attention을 수행하면 model이 서로 다른 위치에 있는 서로 다른 표현 부분 positions에 공동으로 attend 할 수 있다. single-attention head의 경우 평균화를 이를 억제한다.

이 때, projection이 이루어질 때의 parameter matrices는 다음과 같다.
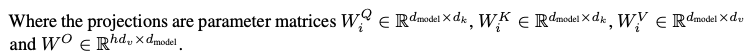
실제 논문에서는 h = 8개의 parallel attention layers 혹은 head를 사용하였다. 이들 각각에 대해 d_k = d_v = d_model / h = 64이다. 각 head의 축소된 차원으로 인해, 총 computational cost는 전체 차원을 갖는 single-head attention과 유사한 성능을 보인다.
Applications of Attnetion in our Model
Transformer는 다음 세 가지 방식으로 multi-head attention를 사용한다.
1)
"encoder-decoder attention" layers에서 query는 previous decoder layer에서 가져오고, memory key와 value는 encoder output에서 가져온다. 이를 통해 decoder의 모든 position이 input sequence의 모든 position을 처리할 수 있다. 이는 sequence-to-sequence model에서 일반적인 encoder-decoder attention mechanisms를 모방한다.
sequence-to-sequence
: output 바로 이전 input까지만 고려하는 RNN의 고질적 문제를 해결하기 위해, encoder, decoder이라고 불리는 두 개의 RNN으로 구성된 model이다. input sequence를 살펴본 후, 고정된 크기의 context vector를 출력하고 decoder 전체적인 맥락이 담긴 context vector를 읽어 output sequence를 생성한다. Seq2Seq model은 sequence 길이와 순서를 자유롭게 하여 두 언어간의 번역과 같은 task에 이상적인 장점이 있다. 그러나 LSTM의 한계와 마찬가지로 input sequence가 너무 길면 vanishing gradient 문제로 효율적으로 학습이 불가능하고, 하나의 고정된 크기의 vector에 모든 정보를 압축하여 손실이 발생하는 단점이 존재한다.
2)
encoder에는 self-attention layer가 포함되어 있다 .self-attention layer에서 모든 query, key, value는 같은 위치에서 온다. 이 경우, encoder에서 previous layer의 output이다. encoder의 각 position은 encoder의 previous layer에 있는 모든 position을 처리할 수 있다.
3)
유사하게, decoder의 self-attention layer는 decoder의 각 position이 decoder의 모든 position에 해당 position을 포함하도록 한다. auto-regressive 속성을 유지하려면 decoder에서 왼쪽으로 정보 흐름을 방지해야 한다. 잘못된 연결에 해당되는 softmax input의 모든 값을 masking으로 설정하여 scaled dot-producted Attention 내부에서 이를 구현한다.
3) Position-wise Feed-Forward Networks
attention sub-layer 외에도, encoder 및 decoder의 각 layers에는 각 position에 개별적으로 동일하게 적용되는 fully connected feed-forward network가 포함된다. 이것은 사이에 ReLU activation이 있는 두 개의 linear transformation로 구성된다.
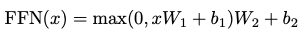
linear transformation은 다른 position에서 동일하지만, layer마다 다른 매개변수를 사용한다. 이를 다르게 설명하자면, kernel 크기가 1인 두개의 convolutions라고 할 수 있다. input 및 output dimension d_model = 512이고, inner-layer dimension은 d_ff = 2048이다.
4) Embeddings and Softmax
다른 sequence tranduction model과 유사하게 학습된 embedding을 사용하여 input 및 output token을 dimension vecotr d_model로 변환한다. 또한 일반적인 학습된 linear transformation 및 softmax function을 사용하여 decoder output을 predicted next-token probabilities로 변환한다. model에서는 두 개의 embedding layer와 pre-sofrmax linear transformation 간에 동일한 weight matrix을 공유한다. embedding layer에서 이러한 weight를 √d_model로 곱한다.
5) Positional Encoding
model에는 recurrence나 convolution이 포함되어있지 않기 때문에, model이 sequence order를 사용하려면 sequence에서 token의 상대 또는 절대 position에 대한 정보를 주입해야 한다. 이를 위해 encoder 및 decoder stack의 맨 아래에 있는 input embedding에 "positional encoding"을 추가한다. positional encoding은 embedding과 동일한 dimension d_model을 가지므로 둘을 합산할 수 있다. positional encodingin 방식에는 여러가지가 있다.
논문에서는 서로 다른 frequencies를 갖는 sine & cosinee function을 사용한다.
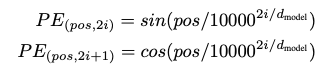
여기서 pos는 position, i는 dimension이다. 즉, positional encoding의 각 dimension은 sinusoid에 해당한다. 파장은 2pi에서 1000 · 2pi까지 기하학적 진행을 형성한다. fixed offset k에 대해 PE_(pos+k)가 PE_pos의 linear function으로 표현될 수 있기 때문에 model이 상대 position에 의해 참석하는 것을 쉽게 학습할 수 있다고 가정해 이 function을 선택했다고 한다. 실험 결과 두 버전이 거의 동일한 결과를 생성했고, 그 중 sin을 선택하였는데, 그 이유는 model이 훈련 중에 발생한 것보다 더 긴 sequence 길이로 extrapolate 할 수 있기 때문이다.
Reference
https://arxiv.org/pdf/1706.03762.pdf
https://glee1228.tistory.com/3
밑바닥부터 이해하는 어텐션 메커니즘(Attention Mechanism)
glee1228@naver.com 며칠 전부터 포항공대 한보형 교수팀과 구글 콜라보의 논문인 Large-Scale Image Retrieval with Attentive Deep Local Features, 이른바 DELF(Deep Local Feature) 로 잘 알려진 논문을 보기..
glee1228.tistory.com
https://sanghyu.tistory.com/107
Transformer (Attention is All You Need) 논문 리뷰
(개인공부를 위해 reference자료들을 정리한 포스팅입니다.) 자연어처리에서 시작되어 다양한 시계열 데이터처리에 사용되는 self-attention개념을 제안한 논문이다. 이름부터 패기가 느껴지는 attentio
sanghyu.tistory.com
https://www.youtube.com/watch?v=mxGCEWOxfe8
'개인 정리 > 개념 정리' 카테고리의 다른 글
| Multi-Objective RL using Sets of Pareto Dominating Policies (0) | 2022.04.04 |
|---|---|
| Deep RL Policy-based Method (0) | 2022.03.04 |
| Deep RL Value-based Methods (0) | 2022.03.03 |
| Traditional RL (0) | 2022.03.02 |
| Combinatorial Optimization by POMO (0) | 2022.03.01 |
| Model-free RL, Model-based RL (0) | 2022.02.07 |




댓글